算法工程索引
汇总本站算法工程相关文章,覆盖排序、哈希、树、字符串、近似数据结构、SIMD、随机化与编译器相关算法。
字符串匹配,是开发工作中最常见的问题之一。它要求从一个较长的字符串中查找一个较短的字符串的位置。例如从字符串 \(T=bacbababaabcbab\) 中查找字符串 \(P=ababaca\) 的位置。 \(T\) 称为*主串*, 字符串 \(P\) 称为*模式串*。
这个问题历史悠久而且经常出现,因此有很多解决这个问题的算法。
通常最容易想到的是朴素匹配算法,也叫暴力求解。简单地说,就是对 \(T\) 中所有可能位置逐一与 \(P\) 匹配。 例如 \(T=badcab\) , \(P=dca\) :
badcab dca -- 比较 dca 与 bad, 不匹配 dca -- 比较 dca 与 adc, 不匹配 dca -- 比较 dca 与 dca,匹配,返回当前位置 2
匹配代码如下:
#include <iostream> #include <string> #include <vector> using namespace std; int search(const string &T, const string&P) { if (P.empty()) { // 模式串为空,匹配任意字符串 return 0; } // i<=T.size()-P.size() 是为了 T[i+j] 不越界 for (size_t i = 0; i <= T.size() - P.size(); ++i) { for (size_t j = 0; j < P.size(); ++j) { if (T[i + j] != P[j]) { break; } if (j == P.size() - 1) { return i; } } } return -1; // -1 表示没有匹配 }
设 \(n=T.size()\) , \(m=P.size()\) , 显然这个算法的复杂度是 \(O(nm)\) 。
这个算法简单,有效,不容易出错。大部分情况下,暴力求解够用了。在我的 PC 上,算法复杂度带入参数后, 计算 \(1e7\) 以下的算法, 基本可以在1秒内完成。
暴力求解里面,内层循环用来匹配每个位置对应的子串是否和模式串匹配。 这个比较过程是可以优化的。
我们将 a-z 这26个字符映射到 0-25,将字符串当作 26 进制整数进行匹配,就可以高效地进行模式串 P 的匹配,从而将内层循环去掉。 算法复杂度是 \(O(n)\)
RK 算法的精髓在于如何快速计算子串的哈希值。如果我们每次都重新计算长度为 \(m\) 的子串哈希,复杂度依然是 \(O(m)\) ,总复杂度还是 \(O(nm)\) 。但是,相邻两个子串之间只有头尾两个字符不同。

假设当前子串是 \(T[i..i+m-1]\) ,其哈希值为 \(H_i\) 。下一个子串是 \(T[i+1..i+m]\) ,其哈希值为 \(H_{i+1}\) 。我们可以用 \(O(1)\) 的时间推导出 \(H_{i+1}\) :
\[ H_{i+1} = (H_i - T[i] \times 26^{m-1}) \times 26 + T[i+m] \]
这个算法的缺点是整数可能溢出。解决办法是使用其它哈希方法,例如将字符串哈希为每个字符的和,但这会造成哈希值冲突,为了解决冲突,需要在哈希值匹配之后,对字符串逐一比较。如果存在大量哈希冲突,每次都要再对比字串,因此这样的方法最差时间复杂度是 \(O(nm)\) 。实际上除非模式串较大,否则遇到哈希冲突的情况是非常少的。受到 Bloom-filter 算法的启发,我曾同时使用 8 个不同的哈希函数计算匹配哈希值,模式串不长所以基本不会冲突,速度很快。缺点就是总被人问“你搞的什么鬼”。后来有人改成了KMP 算法,业务上线2年后发现写错了,review 名单里面也有我, 尴尬的很。写错的算法还不如暴力求解。
让我们仔细查看 \(T=abcacabdc\) , \(P=abd\) 情况,尝试使用暴力求解方法对其匹配。
abcacabdc 1: abd| | | -- 不匹配 2: abd | | -- 不匹配 3: abd| | .. 4: abd | .. 5: abd| -- 不匹配 6: abd -- 匹配!
第1轮匹配时,主串出现字符 \(c\) , \(c\) 并没有在模式串中出现,其实可以直接将模式串整体后移到主串的 \(c\) 之后。
第2轮匹配时,模式串 \(d\) 对应对应主串的 \(a\) ,不匹配,右移1字节。如果知道 \(a\) 在模式串中最后出现的位置是 0, 那么直接后移2字节,让主串的 \(a\) 直接与模式串的 \(a\) 对正,可以节省很多时间。
暴力求解中,模式串与主串按照下标顺序从小到大匹配,BM 算法反而从大到小匹配。从模式串末尾向前倒着匹配,当发现某个字符无法匹配的时候,主串的这个字符就称为 "坏字符"。如上例中的第1轮匹配的 \(c\) ,也如上例中第4轮匹配的最右侧 \(a\) 。
下面这一轮匹配,坏字符 \(c\) 在模式串中不存在, 可以直接将模式串移动到 \(c\) 后面。
abcacabdc abd abd
下面这一轮匹配,坏字符 \(a\) 在模式串中的位置为 0, 可以直接将模式串右移 2 字节,另模式串的 \(a\) 与主串的坏字符 \(a\) 对正。
abcacabdc abd abd
实际上,坏字符出现时,我们将模式串右移,直到模式串中最右侧出现坏字符相同的字符,与主串的坏字符对正。
坏字符规则显然正确,只是,单纯使用坏字符规则还是不够的, \(T=aaaaaaaaaaaaaaaaaaa\) , \(P=baaa\) 的情况下,使用坏字符规则时,跟暴力求解方法时一样的。
好后缀规则与坏字符规则类似。我们观察 \(T=abcacabcbcbacabc\) , \(P=abcabc\) 的匹配。
v __ abcacabcbcbacabc abbccbc abbccbc -- --
可以看到 "cabc" 匹配之后,出现了坏字符 \(a\) 。此时我们关注已经匹配成功的后缀 "bc" (称为**好后缀**)。我们希望将模式串向右移动,使得模式串中另一个 "bc" 与主串的 "bc" 对齐。
为了实现这一点,我们需要预处理模式串,分三种情况考虑:
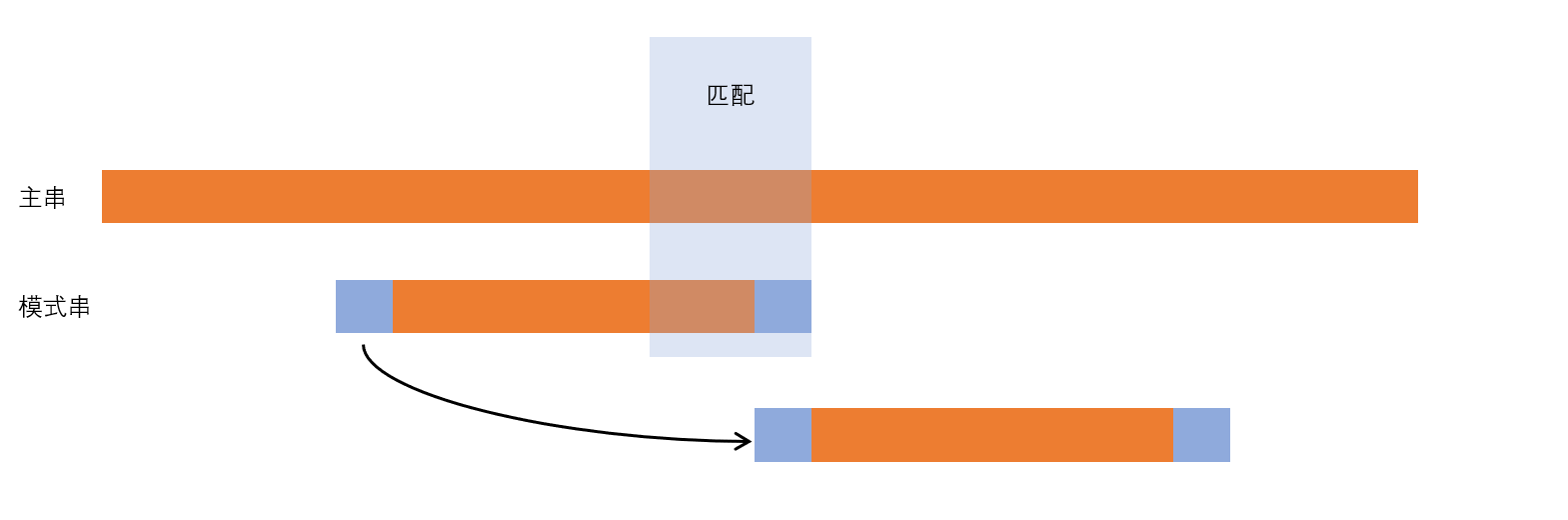
我们很容易预先理解模式串,了解其后缀与等于后缀的最长前缀位置,出现了坏字符时,直接将模式串右移,直到模式串中的前缀与已经匹配的好后缀相等的位置。如果字符串中有多个子串与后缀匹配,就选择最右边的子串。
不难看出目前为止的好后缀规则与坏字符规则相似。
但是,当好后缀在模式串中找不到相同的子串字母移动?象暴力求解一样只右移1字节吗?这种情况可以观察下图,蓝色部分为模式串中前缀等于后缀的部分。由于已经匹配的好后缀在模式串中没有其它对应,退而求其次,右移模式串,直到前缀与后缀相等的位置。
如果模式串中间也出现一个蓝色部分,与其中蓝色的前缀、后缀相等,这是不需要考虑的。因为即使移动中间蓝色部分到后缀蓝色部分相等,由于匹配的好后缀前提已经没有在模式串中有其它对应了,即使将蓝色子串对应,最终也找不到好后缀从而再次右移。
坏字符规则很容易实现,只要构建一个表,可以查找某个字符在模式串中最后出现的位置即可。
问题是好后缀规则如何高效实现。
我们引入 \(suffix\) 数组, \(suffix[i]\) 表示长度为 \(i\) 的后缀在模式串中相匹配的另一个子串的位置。例如 \(P=cabcab\) :
| 后缀子串 | 长度(i) | suffix[i] | prefix[i] |
|---|---|---|---|
| b | 1 | 2 | false |
| ab | 2 | 1 | false |
| cab | 3 | 0 | true |
| bcab | 4 | -1 | false |
| abcab | 5 | -1 | false |
\(suffix\) 数组可以解决好后缀在模式串中有其它匹配的子串的情况。当没有子串与好后缀匹配时,还需要 \(prefix\) 数组。 \(prefix[i]\) 表示长度为 \(i\) 的后缀与模式串前缀是否相等。
实现代码如下:
// 字符集大小 const static int kMaxChar = 256; // 坏字符 vector<int> generate_bad_char(string P) { vector<int> bc(kMaxChar); fill(bc.begin(), bc.end(), -1); // 初始化 for (int i = 0; i < P.size(); ++i) { bc[P[i]] = i; } return bc; } // 好后缀 void generate_good_suffix(string P, vector<int>&suffix, vector<bool>&prefix) { suffix = vector<int>(P.size()); prefix = vector<bool>(P.size()); fill(prefix.begin(), prefix.end(), false); fill(suffix.begin(), suffix.end(), -1); // P[0..i] ~=? P[...P.size()-1] for (int i = 0; i < P.size() - 1; ++i) { int j = i; int k = 0; // 公共后缀子串的长度 while (j >= 0 && P[j] == P[P.size() - 1 - k]) { // P[j..i] 与 P[...P.size()-1] 匹配 --j; ++k; suffix[k] = j + 1; } if (j == -1) { // 后缀与前缀匹配 P[0..i] = P[...P.size()-1] prefix[k] = true; } } } // j 表示坏字符对应 P 的下标 // m 表示 P.size() int move_gs(int j, int m, vector<int>suffix, vector<bool>prefix) { int k = m - 1 - j; // 好后缀长度 if (suffix[k] != -1) { // P 中存在其他好后缀匹配 return j - suffix[k] + 1; } for (int r = j + 2; r <= m - 1; ++r) { // 查找最长匹配的前缀 if (prefix[m - r]) { return r; } } // 都没匹配,就直接右移整串 return m; } int bm(string T, string P) { if (P.empty()) { // 模式串为空,匹配任意字符串 return 0; } if (P.size() > T.size()) { // 模式串比主串还大,肯定不匹配 return -1; // 不匹配返回 -1 } auto bc = generate_bad_char(P); vector<int> suffix; vector<bool> prefix; generate_good_suffix(P, suffix, prefix); int i = 0; // 匹配位置 while (i <= T.size() - P.size()) { int j; for (j = P.size()-1; j >= 0; --j) { // 模式串从后往前 P[j] .. P[0] if (T[i+j] != P[j]) { break; // 找到坏字符 T[i+j] } } if (j < 0) { return i; // 没有坏字符,匹配成功 } int x = j - bc[T[i+j]]; // 坏字符是 T[i+j] int y = 0; if (j < P.size() - 1) { // 存在好后缀 y = move_gs(j, P.size(), suffix, prefix); } i += max(x, y); } return -1; }
BM 的算法复杂度分析很难,Tight Bounds On The Complexity Of The Boyer-Moore String Matching Algorithm 证明 BM 算法的比较次数上限是 \(3n\) 。
我从来没有在实际工作中实现过 KMP 算法,倒是有不少人,正好最近看了 KMP 或者红黑树之后就到面试官职位上显摆,让人手写一个,最近正好看过倒也不难。 虽然平时没什么用,但算法对人思维的启发性也是有意义的,因为与其类似的 AC 自动机算法经常要自己实现。
KMP 算法的思想与 BM 算法类似。它顺序比较模式串,如果遇到坏字符,就向右移动直到前缀匹配到好前缀。 观察下面的例子。
v ababaeabac ababacd --- \ \ --- ababacd
匹配到坏字符 \(e\) 时, \(P\) 的好前缀 \(ababa\) 已经确定匹配了。我们发现:
ababa ababa
这个好前缀的前缀与后缀有一个最长的匹配,我们右移 \(P\) 时,可以直接移动到令这个最长匹配对应。
为了确定移动的步数,我们需要分析模式串本身的结构。对于模式串的每一个子串 \(P[0..i]\) ,我们寻找一个最长的长度 \(k\) ,使得该子串的**前缀** \(P[0..k-1]\) 与**后缀** \(P[i-k+1..i]\) 完全相同。

例如对于子串 `ABABA` :
这意味着,如果我们匹配到了 `ABABA` 后面的字符失配了,我们可以安全地认为,末尾的 `ABA` 已经匹配成功了。而根据模式串的自相似性,开头的 `ABA` 和末尾的 `ABA` 是一样的。所以,我们可以直接把模式串向右滑动,让开头的 `ABA` 对齐到刚才末尾 `ABA` 的位置,然后从第 4 个字符开始继续比较。
`next` 数组是 KMP 算法的灵魂。它的物理含义是:**当模式串在第 `i` 位失配时,我们可以跳到哪个位置继续匹配,而不需要回退主串指针**。
为了实现这一点,我们需要知道模式串的每一个子串 \(P[0..i]\) 内部的自相似性。具体来说,就是寻找这个子串的**最长公共前后缀**。
对于子串 \(P[0..i]\) :
我们需要记录的是**最长**的那个公共前后缀的长度。
在代码实现中,为了方便跳转,我们通常定义 \(next[i]\) 为:子串 \(P[0..i]\) 的最长公共前后缀的**最后一个字符的下标**。如果长度为 \(len\) ,则 \(next[i] = len - 1\) 。如果不存在公共前后缀,则 \(next[i] = -1\) 。
例如字符串 \(P=ababacd\) :
| i | 子串 P[0..i] | 最长公共前后缀 | 长度 (len) | next[i] (len-1) | 说明 |
|---|---|---|---|---|---|
| 0 | a | 无 | 0 | -1 | |
| 1 | ab | 无 | 0 | -1 | |
| 2 | aba | a | 1 | 0 | P[0] == P[2] |
| 3 | abab | ab | 2 | 1 | P[0..1] == P[2..3] |
| 4 | ababa | aba | 3 | 2 | P[0..2] == P[2..4] |
| 5 | ababac | 无 | 0 | -1 | 'c' 破坏了循环 |
| 6 | ababacd | 无 | 0 | -1 |
计算 \(next\) 数组使用的是类似动态规划的方法。我们不需要每次都重新比较前缀和后缀,而是利用已经计算出的结果。
假设我们已经计算出了 \(next[0], next[1], ..., next[i-1]\) ,现在要计算 \(next[i]\) 。设 \(k = next[i-1]\) 。这意味着 \(P[0..i-1]\) 拥有长度为 \(k+1\) 的最长公共前后缀,即: \[ P[0..k] == P[i-1-k..i-1] \]
现在我们考察 \(P[i]\) 和 \(P[k+1]\) 的关系:
情况 B:字符不匹配 (\(P[i] \neq P[k+1]\)) 这意味着我们不能简单地延长原来的公共前后缀。我们需要找一个**更短的**公共前后缀,看看能不能接上 \(P[i]\) 。
去哪里找更短的公共前后缀? 注意,我们已知的公共前后缀是 \(P[0..k]\) 。如果我们想找一个更短的公共前后缀,它必然也是 \(P[0..k]\) 的一个公共前后缀!
所以,我们令 \(k = next[k]\) 。这相当于在 \(P[0..k]\) 这个前缀内部,再找它的最长公共前后缀。
重复这个过程,直到:
vector<int> gen_next(string P) { vector<int> next(P.size()); if (P.empty()) { return next; } next[0] = -1; // P[0] 没有前后缀,初始化为 -1 int k = -1; // k 表示当前匹配的最长公共前后缀的最后一个字符的下标 // 从 i = 1 开始逐个计算 next[i] for (int i = 1; i < P.size(); ++i) { // 如果 P[i] 和 P[k+1] 不匹配,则回退 k // k = next[k] 是 KMP 的精髓:利用已经计算好的 next 数组快速回退 while (k != -1 && P[k+1] != P[i]) { k = next[k]; } // 如果匹配成功,公共前后缀长度 +1 (即 k 向后移动一位) if (P[k+1] == P[i]) { ++k; } // 记录结果 next[i] = k; } return next; } int kmp(string T, string P) { if (P.empty()) { // 模式串为空,匹配任意字符串 return 0; } if (P.size() > T.size()) { // 模式串比主串还大,肯定不匹配 return -1; // 不匹配返回 -1 } auto next = gen_next(P); int j = 0; // j 指向模式串 P 中当前待匹配的字符下标 // i 指向主串 T 中当前待匹配的字符下标 for (int i = 0; i < T.size(); ++i) { // 如果字符不匹配,利用 next 数组回退 j // j-1 是因为 next[x] 存储的是下标 x 对应的最长公共前后缀结尾下标 // 我们需要看的是前一个字符 (j-1) 的 next 值,来决定 j 跳到哪里 // next[j-1] 是匹配的前缀的末尾下标,长度是 next[j-1]+1 // 所以新的 j 应该是 next[j-1] + 1 while (j > 0 && T[i] != P[j]) { j = next[j - 1] + 1; } // 如果字符匹配,j 向后移动 if (T[i] == P[j]) { ++j; } // 如果 j 移动到了 P 的末尾,说明完全匹配 if (j == P.size()) { return i - P.size() + 1; } } return -1; }
KMP 算法的复杂度不难计算。 \(next\) 数组构建时, while 循环分析有点麻烦。可以这么想: 每次循环,\(k\) 要么增加1,要么减少。增加的地方只有 \(++k\) , 在 for 循环中,所以最多执行 \(m-1\) 次。 \(k\) 减少是在 while 循环中,因为它最小值 \(-1\) 后不可能再递减,所以最多执行 \(m-1\) 次。 因此计算 \(next\) 数组的时间复杂度是 \(O(m)\) 。
同理,匹配 \(T\) 时复杂度是 \(O(n)\) 。 KMP 的总体时间复杂度是 \(O(n+m)\) 。
在 KMP 算法中,标准的 \(next\) 数组在某些情况下还可以进一步优化。考虑模式串 \(P=aaaaa\) ,主串 $T=aaaba…$ 。当匹配到 \(T[3]=b\) 与 \(P[3]=a\) 失配时,根据 \(next\) 数组,我们会回退到 \(next[2]\) 等位置。但如果回退后的位置对应的字符依然是 \(a\) ,那么它肯定依然会与 \(b\) 失配。这种多余的比较是可以避免的。
优化后的 \(next\) 数组通常称为 \(nextval\) 。其核心思想是:如果回退后的字符与当前字符相同,则继续回退,直到找到一个不同的字符或者回退到头。
// 生成优化后的 next 数组 (nextval) vector<int> gen_nextval(const string& P) { // 1. 先计算标准的 next 数组 vector<int> next(P.size()); if (P.empty()) return next; next[0] = -1; int k = -1; for (int i = 1; i < P.size(); ++i) { while (k != -1 && P[k + 1] != P[i]) { k = next[k]; } if (P[k + 1] == P[i]) { ++k; } next[i] = k; } // 2. 基于 next 数组计算 nextval // 逻辑:如果 P[i+1] == P[next[i]+1],则说明回退后遇到的字符和当前一样, // 肯定还是不匹配,所以可以直接继续回退。 vector<int> nextval = next; for (int i = 0; i < P.size(); ++i) { if (i + 1 < P.size()) { int j = next[i]; // j 是 P[0..i] 的最长公共前缀后缀的末尾下标 // 如果回退后的下一个字符 P[j+1] 与当前失配字符 P[i+1] 相同 if (j != -1 && P[i + 1] == P[j + 1]) { // 递归优化:直接指向 nextval[j] // 注意:因为是从前往后遍历,nextval[j] 此时已经是优化过的值了 nextval[i] = nextval[j]; } } } return nextval; } int kmp_optimized(const string& T, const string& P) { if (P.empty()) return 0; if (P.size() > T.size()) return -1; auto nextval = gen_nextval(P); int j = 0; for (int i = 0; i < T.size(); ++i) { // 使用 nextval 数组进行跳转,逻辑与标准 KMP 完全一致 while (j > 0 && T[i] != P[j]) { j = nextval[j - 1] + 1; } if (T[i] == P[j]) { ++j; } if (j == P.size()) { return i - P.size() + 1; } } return -1; }
Sunday 算法由 Daniel M. Sunday 在 1990 年提出。它的思想比 BM 算法更简单,但在实际应用中(特别是处理英文文本时)往往比 BM 和 KMP 更快。
Sunday 算法的核心思想是:**关注主串中位于模式串末尾的下一个字符**。
当匹配失败时,我们直接查看主串中当前对齐的模式串后面紧接着的那个字符(设为 \(c\) )。

Sunday 算法实现
int sunday(const string& T, const string& P) { if (P.empty()) return 0; if (T.size() < P.size()) return -1; // 建立偏移表 // shift[c] 表示字符 c 在模式串中最右出现位置到末尾的距离 + 1 // 或者理解为:遇到字符 c 时,模式串需要向右移动的步数 vector<int> shift(256, P.size() + 1); for (int i = 0; i < P.size(); ++i) { shift[P[i]] = P.size() - i; } int i = 0; while (i <= T.size() - P.size()) { // 尝试匹配 int j = 0; while (j < P.size() && T[i + j] == P[j]) { ++j; } if (j == P.size()) { return i; // 匹配成功 } // 匹配失败,查看 T[i + P.size()] if (i + P.size() >= T.size()) { break; } // 根据偏移表移动 i += shift[T[i + P.size()]]; } return -1; }
By ltl.
把当前热点继续串成多页阅读,而不是停在单篇消费。
汇总本站算法工程相关文章,覆盖排序、哈希、树、字符串、近似数据结构、SIMD、随机化与编译器相关算法。
持久化数据结构原理与实现:探索 undo/redo、MVCC、Git 等系统背后的数据结构设计模式
二分查找算法详解:原理、实现、变种及常见错误分析,O(log n) 时间复杂度的高效搜索算法
Heavy Hitters 算法:如何高效计算高频数据项,在流式数据处理和热门页面统计中的应用