leveldb 日常使用
LevelDB 使用指南:Google 开发的高性能 Key-Value 数据库实践教程
Leveldb 实现了key-value形式的缓存,淘汰算法是LRU。实现代码在 leveldb/util/cache.cc,一共400行,非常简洁。我曾以为他提供的一些逻辑是多余的,在工作中遇到同样需求时尝试精简这个实现,后来发现我是错的,最终只改了注释上的拼写错误。
我们先尝试设计一个key-value的缓存,淘汰算法同样是lru。既然是 key-value 结构,为了方便查询,就必须有个树形结构,或者哈希结构,或者跳表。就选择哈希结构吧,因为实现简单,效率也很高。如果哈希函数出现冲突,就用链表将冲突的key链接起来。就像这样:
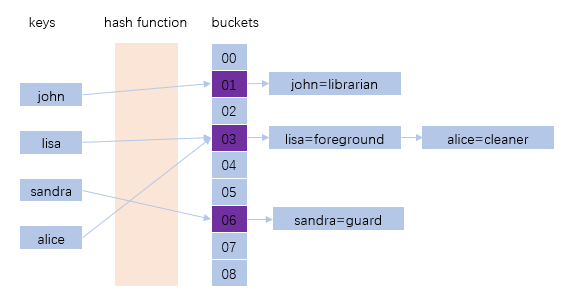
哈希表解决了key-value映射的问题,接下来要考虑的是如果哈希表中存储的内容超过了规定大小,如何使用lru算法淘汰调旧的key-value对。可以使用的方案有:
点移动到链表尾部,这样链表头就是最老的节点,每次淘汰链表头节点。
方案1在每次淘汰时都要扫描全表,这样的时间复杂度显然是不可接受的。方案3虽然新奇,大O时间复杂度也可以接收,但常数太大了,最重要的是太奇葩。方案2可以,复杂度和哈希表一样,每次操作哈希表都要更新链表一个节点。
于是这个结构就变成了这样:
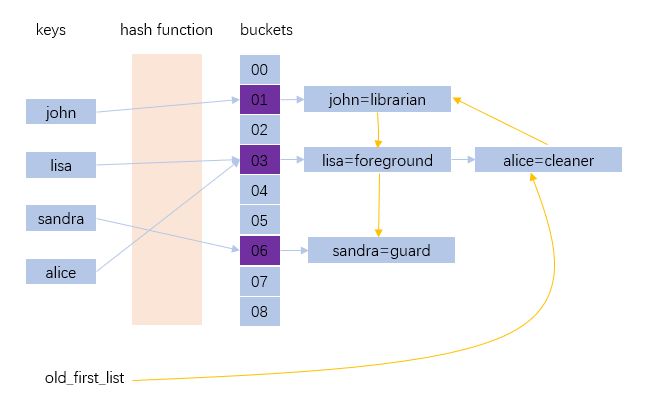
old_first_list 将所有哈希节点链在链表中,如图,alice是链表中第一个节点,他是最老的,john是第二老的,lisa是次新的,sandra是最新的节点。每次要淘汰时,只要沿着 old_first_list 链表淘汰,直到满足限制条件。这个方案,暗藏着一些的问题:
释放节点的资源。
引用的节点,再将这个节点删除,这个复杂度也是比较差的。
Leveldb 使用引用计数,而且用两个链表,双份的快乐。引用计数保证是仍有外部引用的情况下,不淘汰这个节点;两个链表保证淘汰按照LRU顺序淘汰,同时保证时间复杂度可以接受。
in_use_ 链表维护正在被外部引用的节点,当所有外部引用都释放,节点从in_use_链表移到 lru_链表。lru_链表,lru_链表头部是最老的没有访问过的节点,lru_链表尾是最新的被访问过的节点。每次淘汰时,都从lru_链表头开始淘汰,直到满足空间要求。
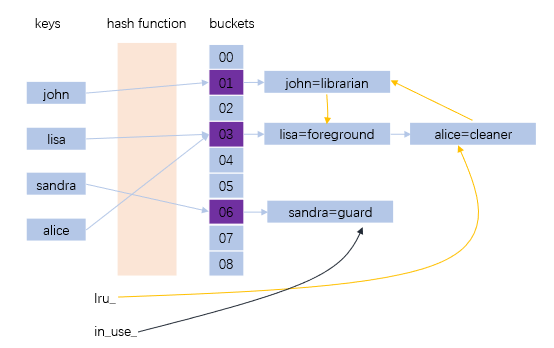
那么,in_use_这个链表不是没用吗? 还在被引用的节点就这么放着,直到没被引用之后插入到lru_ 链表不就行了吗?是的,in_use_ 只是为了让next_hash有个地方去,代码实现方便点,把 in_use_链表删了也没有太多实质收获。正在用的节点放在 in_use_ 链表里,还能让人看的明白点:被外部引用的节点都在这里,而不是什么地方也不在…
挺有道理的。
对吧?
后面的内容适合配合源码阅读。其实直接阅读源码也是可以的,leveldb源码非常清晰,现在就可以关闭网页直接阅读源码,真的看不懂还能再回来。
节点的定义代码很短,但从中能窥视整个缓存结构的设计思路,了解作者为了可读性牺牲了什么,同时为了什么牺牲了可读性。
// An entry is a variable length heap-allocated structure. Entries // are kept in a circular doubly linked list ordered by access time. struct LRUHandle { void* value; void (*deleter)(const Slice&, void* value); LRUHandle* next_hash; LRUHandle* next; LRUHandle* prev; size_t charge; // TODO(opt): Only allow uint32_t? size_t key_length; bool in_cache; // Whether entry is in the cache. uint32_t refs; // References, including cache reference, if present. uint32_t hash; // Hash of key(); used for fast sharding and comparisons char key_data[1]; // Beginning of key Slice key() const { // next is only equal to this if the LRU handle is the list head of an // empty list. List heads never have meaningful keys. assert(next != this); return Slice(key_data, key_length); } };
知道设计思路之后,上面的结构也就没有太多意外了。要说意外也不能说没有。节点的类型名叫 LRUHandle,之后都把节点实例叫 handle 吧。下面逐一解释每个成员的作用。
value 缓存存储的对象,这里类型是 void*,也就是说这个缓存结构可以存储任意类型的值,同时也说明类型由用户确定,淘汰时需要调用用户指定的清理函数来释放这个地址指向的资源。
deleter value是个指针,指向用户指定的任意类型的对象,指向的对象如何释放需要用户指定, deleter就是这样一个函数指针。在初始化时用户需要确定缓存要存什么类型的值,还要编写一个定义如何释放缓存内容的函数。
next_hash 哈希表冲突链表中指向下一个节点的指针。哈希表的冲突链表是个单链表,最后一个节点的 next_hash指向nullptr。
next lru_或者in_use_链表中指向下一个节点的指针,因为handle只可能出现在其中一个链表里,就复用了。
prev 单链表的删除总有人写不对,指针的指针还老有人看不懂,所以用双链表,这是lru_或者 in_use_链表中指向前一个节点的指针。lru_和in_use_是循环双链表,永远构成环。空链表是个空的handle,next和prev都指向自己,虽然浪费一点点内存,可读性却比linux内核的双链表好多了。链表头是个冗余的handle,不存储数据,只用它的next和prev,如果链表为空,头节点的next和prev指向自己构成环,这与linux的list.h很像。
charge 缓存有个capacity_字段,表示可以消耗多少资源,对应就是每个handle的charge字段。资源数的定义是用户指定的,一般都用内存用量吧。
in_cache in_cache为真,表示handle在哈希表中,否则不在哈希表中。用户可能会插入相同的key,指向不同的value,这种情况下,前一次插入的value应该被新的value替换,但如果还有外部引用,就不能将其释放,这种情况下,就会出现哈希表中没有,但仍然没有被释放的 handle。当外部引用释放这个handle时,才会真正调用deleter将其资源释放。in_cache为真时,handle总能在哈希表中找到,总能在in_use_或lru_中找到;如果in_cache为假,无论在哈希表中还是链表中都没有它。
refs 引用计数。在哈希表中记为1,被外部引用记为2,再被外部引用记为3。为什么在哈希表中就是1而不是0呢?结合 in_cache 理性思考,从哈希表删除,计数减一,如果计数为0则释放资源,从外部引用释放,计数减一,如果计数为0则释放资源,这样两种操作就一致了,谁也不能阻止代码减半带来的愉悦。
hash 哈希函数将key映射成的整数值。
key_length key的字节数。
key_data key_data是指向key数据的第一个字节的指针。创建新handle时,申请长度为 sizeof(LRUHandle)-1+key.size() 的内存空间,前 sizeof(LRUHandle)-1字节存储从 value到 hash的数据,后 key.size()字节存储key的数据,这样可以减少一次内存申请。这里不用 \(key\_data[0]\) 是因为在C11,以及 C++11里是不合法的,编译不过。这种做法并不安全,谁也没办法保证以后没有个孙子派生LRUHandle,或者在LRUHandle中key_data之后加入成员,或者将LRUHandle放在别的结构中作为成员。但作为大神,就应该有心怀“这都能写错怎么还不切腹谢罪”的态度,还有refs结构内部引用也算引用,“注释都看不懂也可以死一死,请”。实际上,大神为了防止别人问起的时候自己也搞不清楚,都标注了至少能给自己多年前写下这份代码时的深层记忆的提示,或者偷偷记在小本本上,哼。
key() 返回key,方便对key的访问。返回类型是Slice,其实就是一段连续的内存空间,这里永远放回的指向这个节点从 key_data开始,长度为 key_length的内存空间。
因为哈希表和handle耦合在一起,也因为自己实现的哈希表比g++实现块约5%,更重要的是因为大神倔强,leveldb缓存自己实现了个哈希表,反正也不到100行代码。
具体实现和普通哈希表没有什么区别,leveldb 的哈希桶根据实际存储handle数调整大小,保证平均冲突链表长度不大于1。
哈希表类名叫 HandleTable,意思是“存储 handle 的表”,大概。HandleTable 的成员一共三个,看起来简单,实际也很简单:
class HandleTable { private: uint32_t length_; uint32_t elems_; LRUHandle** list_; };
length_ 是list_数组的长度,他只能是2的n次方,并且不小于handle的数量,并且至少是4; elems_是存储的handle的个数;list_是保存LRUHandle*类型的数组,其实就是哈希桶,需要多长就new多长。
如果看代码的话,里面比较难懂的就一个函数,FindPointer():
LRUHandle** FindPointer(const Slice& key, uint32_t hash) { LRUHandle** ptr = &list_[hash & (length_ - 1)]; while (*ptr != nullptr && ((*ptr)->hash != hash || key != (*ptr)->key())) { ptr = &(*ptr)->next_hash; } return ptr; }
考虑下面这个图,这是一个哈希桶后面的冲突链表,第一个next_hash就是list_[i]里面存的地址。而ptr是指向next_hash的指针,*ptr就等于其指向的next_hash,**ptr就是handle 的值。
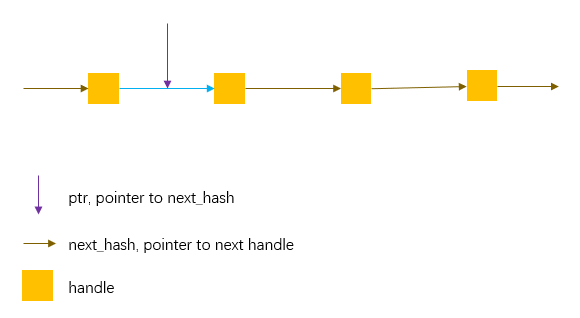
首先ptr找到哈希桶,ptr指向上图中对应桶的第一个next_hash,然后使用这个ptr遍历这个链表,知道找到key相同的节点。如果没找到,ptr就指向最后一个next_hash,这个 next_hash的值是空地址。最后将ptr返回。
ptr这种双指针定义是为了方便节点删除。FindPointer()返回ptr后,要删除ptr指向的节点,只需要 *ptr = (*ptr)->next_hash。
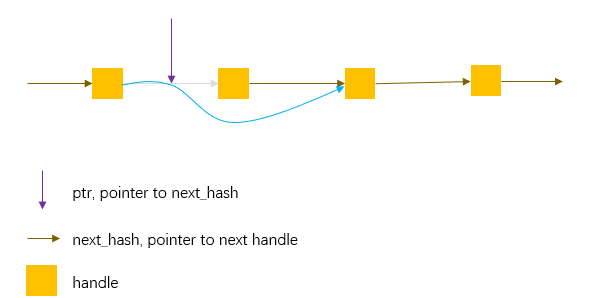
有些见多识广的人可能还有一项在单链表中只给定一个指向handle的指针p的情况下删除这个节点的绝技: *p = *p->next_hash。这是把p指向的handle里面的next_hash和value连同其它值以同赋值为p->next_hash指向的节点,这样p->next_hash的内容存在p上,从链表中删除了p->next_hash节点。看似完美,但是别忘了 \(key\_data[1]\) ,key的内容没有完整复制到p上。我也没想明白这个操作怎么删除最后一个节点。除了这些问题,p->next_hash指向的handle可能是有外部引用的,这种偷梁换柱的办法把这个节点删了,外部引用的就是一个已经删掉的节点。想要了解更多可以参考这里。
有了FindPointer(),查找函数就直接返回FindPointer()返回的指针指向的值,插入直接往 FindPointer()返回的值上插入,删除就直接删除FindPointer()返回值指向的next_hash指向的handle。哈希表里还有个Resize()函数,用于调整哈希桶长度,以保证哈希桶长度不小于存储的handle数量。Resize()重新计算了 length_,length_总是2的n次方,并且不小于 handle数量。然后申请一段length_长度的list_数组,重新计算旧的handle的哈希值,将其移动到新的list_数组对应的桶上。
值得注意的是,leveldb只在handle增长的时候扩大list_,没有缩小,这符合leveldb的使用场景。但如果想在别处使用这个哈希表,可以考虑用Resize()函数缩短list_的长度。我在一个C语言项目中使用了这个实现,保证桶长度缩短时不能小于4和handle数量的四分之一的最大值,增长时不小于handle数量。好吧,我知道你在想什么,这里是C语言版本的实现,批判一番吧。
到这里,应该能猜出lru算法的实现了。
class LRUCache { private: size_t capacity_; mutable port::Mutex mutex_; size_t usage_ GUARDED_BY(mutex_); LRUHandle lru_ GUARDED_BY(mutex_); LRUHandle in_use_ GUARDED_BY(mutex_); HandleTable table_ GUARDED_BY(mutex_); };
毫不意外的,LRUCache结构里有哈希表 table_,有存 lru_链表,有in_use_链表。lru_是个冗余的链表头节点,lru_.prev是最新的节点,lru_.next是最老的节点,lru_保存 refs==1并且in_cache==true的handle。In_use_是个冗余的链表头节点,保存refs>=2并且 in_cache==true的节点。capacity_与handle的charge字段对应,这个结构里所有handle的 charge字段加起来,不能超过capacity_,usage_是所有handle的charge总和。mutex_是互斥锁,保证LRUCache结构的线程安全。
插入新key-value时,先插入in_use_链表,再插入哈希表,如果替换了哈希表中key相同的 handle,就判断是否可以将被替换的handle释放。如果插入导致capacity_条件不满足,则从lru_释放handle直到满足。插入后handle.refs=2,handle使用完毕后必须调用Release接口释放引用。每次调用Lookup接口查询后,引用计数也会增加,同样需要Release接口释放引用。
LRUCache的接口都是有互斥锁的,为了减轻冲突,leveldb实际使用ShardedLRUCache结构来缓存数据。ShardedLRUCache内部默认有16个LRUCache结构,根据哈希值决定到底去哪个 LRUCache结构中操作。
By Liao Tonglang.
把当前热点继续串成多页阅读,而不是停在单篇消费。
LevelDB 使用指南:Google 开发的高性能 Key-Value 数据库实践教程
从零实现 LSM-Tree Compaction:最小堆多路归并迭代器、Level 分层与 Compaction 打分、Tombstone 下推、Version/VersionEdit/MANIFEST 版本管理,以及 Leveled/Size-Tiered/Universal 三种策略的量化对比。从零写一个 LSM-Tree 存储引擎系列第 4 篇。
组装完整 LSM-Tree 存储引擎:DB 接口(Open/Put/Get/Delete/Iterator/Snapshot)、单写多读并发控制、启动恢复,然后用 Rust 重写核心模块,记录 5 个编译器不让我过的故事,最后三方 benchmark 对比。从零写一个 LSM-Tree 存储引擎系列第 5 篇。
从零理解 LSM-Tree 存储引擎的设计哲学:B-Tree 与 LSM-Tree 的本质差异,写放大/读放大/空间放大的三角权衡,以及 WAL、MemTable、SSTable、Compaction、Bloom Filter 各组件的角色与协作关系。从零写一个 LSM-Tree 存储引擎系列第 1 篇。