leveldb 的缓存结构
LevelDB 缓存实现解析:LRU 算法在 Key-Value 数据库中的应用与优化
leveldb是个由Google开发key-value数据库,具有很高的写性能,但是读比较慢。现实世界大多数应用都是写多读少的,所以有人用leveldb作为数据库的存储引擎。直接使用leveldb 的项目比较少见,最常见的是使用 rocksdb,rocksdb是facebook基于leveldb的项目,做了一些优化,性能有些提升,同时提供了更多功能。
首先下载源代码编译生成 libleveldb.a:
git clone git@github.com:google/leveldb.git cd leveldb mkdir build && cd build cmake -DCMAKE_BUILD_TYPE=Release .. make -j
使用leveldb 的程序需要连接 libleveldb.a,并在包含文件目录中加入 leveldb 项目代码里的 include 目录。由于leveldb使用了libpthread,编译时也要链接pthread库。
例如,建立一个文件 test.cc ,文件内容如下:
#include <assert.h> #include <leveldb/db.h> #include <iostream> #include <string> using namespace std; int main(void) { leveldb::DB *db; leveldb::Options options; options.create_if_missing = true; // open leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db); assert(status.ok()); string key = "keytest"; string value = "this is the value of keytest"; // write status = db->Put(leveldb::WriteOptions(), key, value); assert(status.ok()); // read status = db->Get(leveldb::ReadOptions(), key, &value); assert(status.ok()); cout << "value of " << key << " is " << value << endl; // delete status = db->Delete(leveldb::WriteOptions(), key); assert(status.ok()); status = db->Get(leveldb::ReadOptions(), key, &value); assert(!status.ok()); // close delete db; return 0; }
上述例子里,leveltest建立了 /tmp/testdb 目录,这就是数据库存放位置。随后向 /tmp/testdb 数据库存入一个键值对并查询。之后删除键,再查询其值。最后关闭数据库。
使用如下命令编译链接并运行程序:
g++ -c test.cc -Ipath/to/leveldb/include g++ path/to/leveldb/build/libleveldb.a -lpthread -o test ./test
下面这个图片形象地解释了编译链接leveldb库这个无聊的流程:
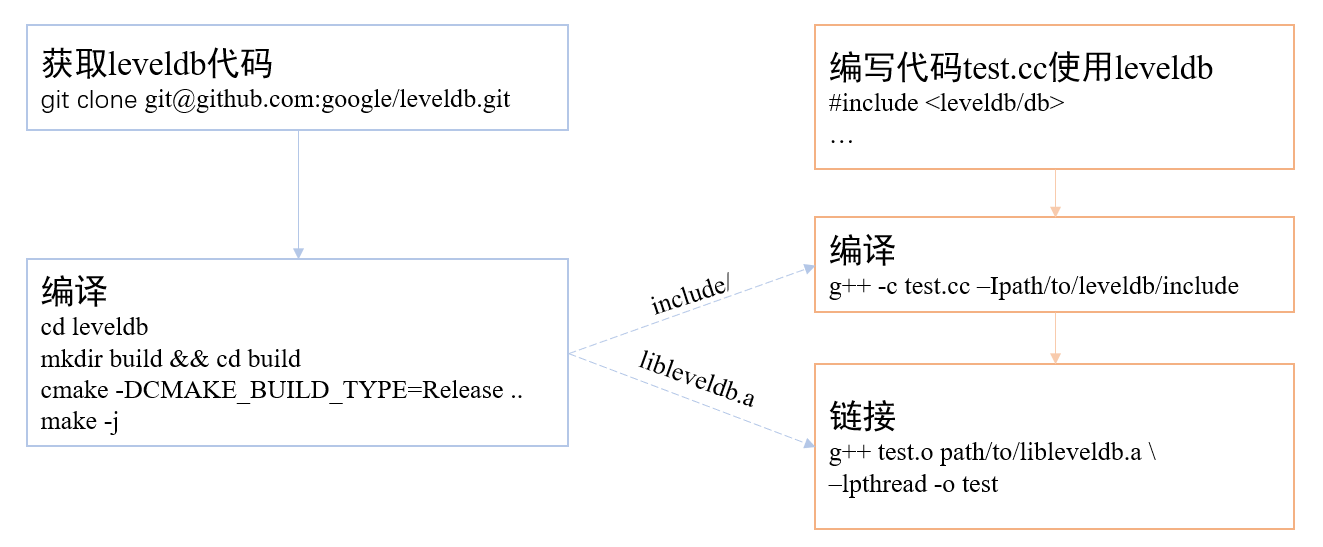
实际项目当然不是像这样手动编译的,我顺手写了个例子,用cmake自动下载leveldb并编译例子程序,原理和上面说的一样,可以 在Github上查看 。
数据库是一个文件系统目录,打开数据库时需要指定这个目录。下面的例子打开 /tmp/testdb这个数据库,如果数据库不存在,则在/tmp/testdb目录创建一个。
leveldb::DB* db; leveldb::Options options; options.create_if_missing = true; leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db); assert(status.ok());
例子里给options.create_if_missing 赋值为 true,意思是如果指定数据库不存在,则创建一个。options参数还有很多,比如block大小,文件最大长度等。leveldb 的优化是个与实际用途和硬件环境关系密切的工作,默认参数一般是足够的,如果非要优化,需要根据自己的运行环境和用途建立数学模型,计算并实验以确定实际参数值。Leveldb::Options 的定义以及每个参数的用途在 include/leveldb/options.h 中能找到。
要关闭数据库,只需要调用 leveldb::DB 的析构函数即可:
delete db;
Leveldb::DB的析构函数不会把数据库删除,只是清理程序中的数据结构,关闭文件,释放内存,下次再打开这个数据库,存储的数据还在。
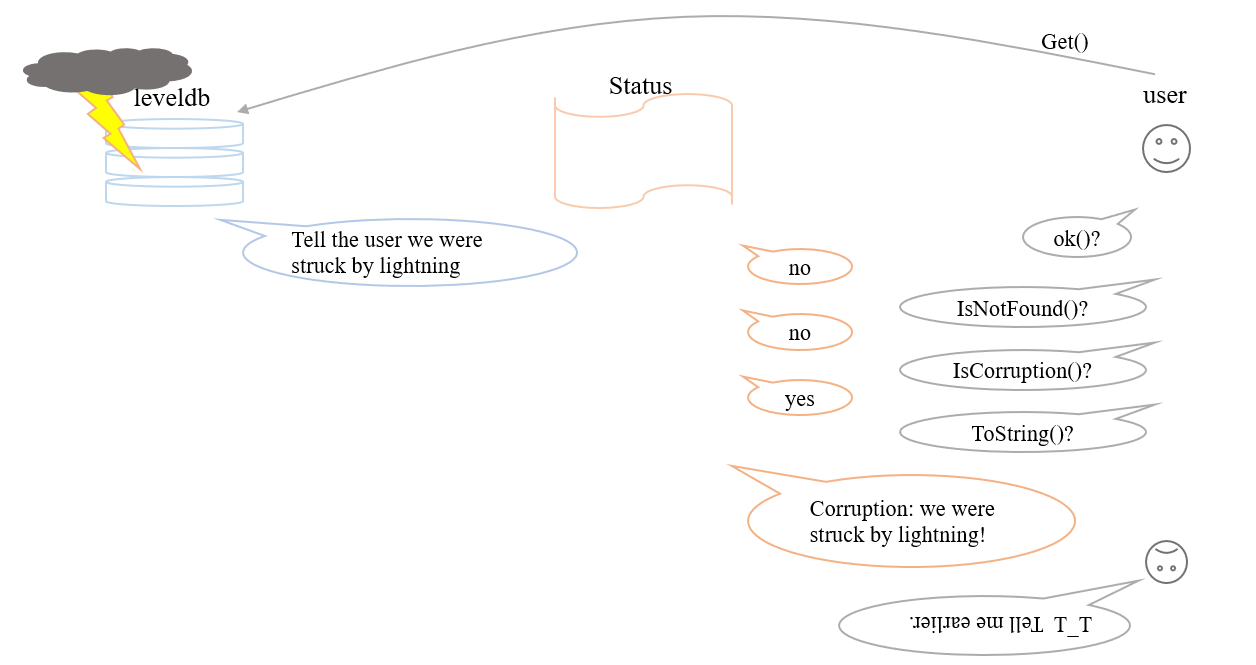
Leveldb 接口中大多数函数的返回值都是Status对象,表示函数调用是否有错,具体定义在 include/leveldb/status.h 中。
leveldb::Status s = ...; if (!s.ok()) cerr << s.ToString() << endl;
S.ok()表示执行成功,s.IsNotFound()表示未找到,s.IsCorruption()表示数据出错, s.ToString() 返回错误信息。
Google 不抛出异常,返回Status对象表示是否成功的方式显然是个好的异常处理方法,与 linux 中的 errno 类似,只是Status更加简洁明了。
有关数据库的创建,删除,读写操作都在 include/leveldb/db.h 中。leveldb提供了 Put, Delete,Get方法来写入,删除,查询数据。
std::string value, key1, key2; leveldb::Status s = db->Get(leveldb::ReadOptions(), key1, &value); if (s.ok()) s = db->Put(leveldb::WriteOptions(), key2, value); if (s.ok()) s = db->Delete(leveldb::WriteOptions(), key1);
在头文件里,参数定义key和value都是slice类型,而slice类定义了从std::string的类型转换,所以参数是std::string类型也是可以的。
同一个key被Put两次以上,那么Get到的就是最近一次Put的数据,也就是说Put可以插入,如果已经有这个key,就更新。
使用 WriteBatch 方法可以将一批更新操作合并为一个操作,如果失败,一次WriteBatch的数据都丢失,如果成功,一次WriteBatch的数据都更新成功。这个原子性在很多时候是必要的。
#include "leveldb/write_batch.h" ... std::string value; leveldb::Status s = db->Get(leveldb::ReadOptions(), key1, &value); if (s.ok()) { leveldb::WriteBatch batch; batch.Delete(key1); batch.Put(key2, value); s = db->Write(leveldb::WriteOptions(), &batch); }
除了原子性这个特性,WriteBatch还可以提升写入效率,多个更新操作合并到WriteBatch会快一些。
Leveldb 的写操作默认是异步的,写函数在将数据提交给操作系统之后返回,数据从内存到磁盘的过程是异步的,由操作系统管理。如果系统崩溃或者断电了,最近的几次写入会丢失。在异步写的情况下,仅仅是程序崩溃,数据是不会丢失的。
为了避免系统崩溃前夕写入函数返回成功但实际数据丢失,同时也为了把写入操作变慢上千倍,leveldb允许同步写入,具体实现是在调用 fsync(), fdatasync(), msync()之后返回。写入时设定WriteOptions的sync成员为真即可。sync是目前WriteOptions唯一的作用。
leveldb::WriteOptions write_options; write_options.sync = true; db->Put(write_options, ...);
一般情况下,异步写是可以满足需求的。如果非要保证数据不丢失,例如,加载较大的数据,可以每隔N个异步写操作加入一个同步写操作,同步写操作写入一个标志,表示这之前的数据都完整写入了,如果系统崩溃了,就从这个标志之后的位置开始导入。将多个写入操作合并到一个WriteBatch上,一次同步完成,也是个常见办法。
同一个leveldb数据库,同一时间只能被一个程序打开。leveldb使用操作系统的锁来保证不会同时访问同一个数据库。Leveldb::DB对象是线程安全的,里面所有方法都不需要额外加锁,但其他的对象,比如WriteBatch,就不是线程安全的,需要外部同步。
leveldb存储是有序的,可以使用迭代器依次访问数据。下面的例子演示了如何打印一个数据库中的所有key value对。
leveldb::Iterator* it = db->NewIterator(leveldb::ReadOptions()); for (it->SeekToFirst(); it->Valid(); it->Next()) { cout << it->key().ToString() << ": " << it->value().ToString() << endl; } assert(it->status().ok()); // Check for any errors found during the scan delete it;
还可以从访问一个范围内的数据:
for (it->Seek(start);
it->Valid() && it->key().ToString() < limit;
it->Next()) {
...
}
逆序访问也是允许的,只是会慢一些:
for (it->SeekToLast(); it->Valid(); it->Prev()) {
...
}
快照是一个leveldb数据库某个时间的状态,是只读的,你也从一个快照中读取这个时间点存储的所有数据。读取的时候要指定ReadOptions::snapshot为获得的快照。
leveldb::ReadOptions options; options.snapshot = db->GetSnapshot(); ... apply some updates to db ... leveldb::Iterator* iter = db->NewIterator(options); ... read using iter to view the state when the snapshot was created ... delete iter; db->ReleaseSnapshot(options.snapshot);
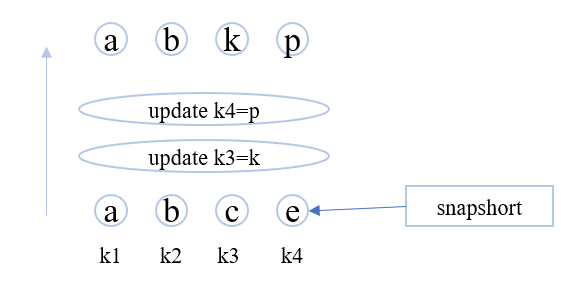
快照用完了记得调用 DB::ReleaseSnapshot 释放。
切片是对一段连续内存的引用,其定义在include/leveldb/slice.h。leveldb很多接口多使用了leveldb::Slice类型,在函数之间传递Slice要比传递std::string高效得多。需要注意的是,Slice仅仅是一个对真正数据的引用,在一个Slice对象还有用途之前,不能将真正的数据删除。
leveldb::Slice slice; if (...) { std::string str = ...; slice = str; } Use(slice);
上面的例子是有问题的,str指向的内存在 if 结束后就释放了,谁用谁崩溃。
Leveldb 的 key 默认是字典序的,他有个默认比较器,这个比较器认为字典序大的就是大,字典序小的就是小。比较器是可以自定义的,可以指定key的顺序遵守某个规则。例如,key 是个指向一个数据结构的slice,数据结构有两个整数,你可以指定按第一个整数排序,如果第一个整数相等,按第二个整数排序,这个比较器就可以这样定义:
class TwoPartComparator : public leveldb::Comparator { public: // Three-way comparison function: // if a < b: negative result // if a > b: positive resul // else: zero result int Compare(const leveldb::Slice& a, const leveldb::Slice& b) const { int a1, a2, b1, b2; ParseKey(a, &a1, &a2); ParseKey(b, &b1, &b2); if (a1 < b1) return -1; if (a1 > b1) return +1; if (a2 < b2) return -1; if (a2 > b2) return +1; return 0; } // Ignore the following methods for now: const char* Name() const { return "TwoPartComparator"; } void FindShortestSeparator(std::string*, const leveldb::Slice&) const {} void FindShortSuccessor(std::string*) const {} };
现在可以这样创建一个数据库:
TwoPartComparator cmp; leveldb::DB* db; leveldb::Options options; options.create_if_missing = true; options.comparator = &cmp; leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db); ...
一个数据库的Comparator必须始终如一,创建的时候使用了什么Comparator,以后的所有读写操作都只能用这个Comparator。Comparator 的名字会存在数据库里,如果不一样, leveldb::DB::Open会失败。如果预感到将来要改变Comparator,可以在插入时,每个key里面加入一个版本字段,编写一个根据版本字段选择如何比较的Comparator,将来要改变时,就添加一个版本,修改Comparator比较逻辑,但不能改变名字。
性能相关的参数,都在 include/leveldb/options.h 里定义。
leveldb把数据组合成块,key相邻的数据会放到相同的块里。块是持久化存储的最小单位,每次从文件读,或者写入文件,都是以块为单位读写的。默认的块大小是4096,这是没压缩过的大小,如果使用压缩算法,实际存储的块会比这个小。经常批量扫描多个数据的应用可能更喜欢较大的块,经常随机访问一个或一小段数据应用可能会喜欢更小的块,压缩算法喜欢较大的块。不管数学有多好,块大小的具体值也要根据实际测试结果确定,因为实际情况往往比模型复杂。小于1k字节的块,或者数兆以上字节的块,是没有意义的。
每个块是单独压缩的,压缩算法执行在块写入持久化存储之前。因为默认的压缩算法很快, leveldb默认开启压缩。如果数据不可压缩,leveldb会选择不压缩,熵高的数据一般不可压缩。少数应用可能不想要压缩,如果基准测试证明应该关闭压缩,就可以关闭:
leveldb::Options options; options.compression = leveldb::kNoCompression; ... leveldb::DB::Open(options, name, ...) ....
数据是存在数个文件中的,每个文件存储了一系列压缩过的块,为了加速读取,一般需要一个块缓存。
#include "leveldb/cache.h" leveldb::Options options; options.block_cache = leveldb::NewLRUCache(100 * 1048576); // 100MB cache leveldb::DB* db; leveldb::DB::Open(options, name, &db); ... use the db ... delete db delete options.block_cache;
Cache 的所有操作在 include/leveldb/cache.h 中能找到,一般也不需要操作。需要注意, Cache 存储的是整个块的压缩之前的数据。操作系统会缓存文件内容在内存中,如果你非要在操作系统和cache之间添加一层缓存,可以自己实现个Env类。
缓存是LRU的,在批量顺序读取的时候你可能不希望频繁更新缓存,因为这次缓存更新之后,接下来的读取会马上将他挤出,这种多余的更新缓存是毫无意义的。这种情况下, ReadOptions提供了一个选项,可以指定在读取的时候不更新缓存:
leveldb::ReadOptions options; options.fill_cache = false; leveldb::Iterator* it = db->NewIterator(options); for (it->SeekToFirst(); it->Valid(); it->Next()) { ... }
Leveldb 把大小(由Comparator指定的大小顺序)相邻的key存放在一起,一般相邻的key就一起放在相同的块中。所以,在编写应用程序时,可以将经常一起访问的数据用相邻的key保存,不一起访问的key用距离大的key保存。例如,要在leveldb上实现一个文件系统,可以把文件名,路径等key存放在一起(加个相同的前缀),把文件内容放在另一个地方(另一个前缀),这样,在路径中浏览时就不需要加载并缓存文件内容了。
leveldb数据的组织方式利于写入,不利于读取,一次Get可能需要使用好几次文件访问才能完成。leveldb使用过滤器减少文件读取操作,读文件之前先使用过滤器检查数据是否可能存在于这个文件中,如果不存在,就不需要再读取这个文件其他内容了。leveldb提供了 BloomFilterPolicy作为过滤器:
leveldb::Options options; options.filter_policy = NewBloomFilterPolicy(10); leveldb::DB* db; leveldb::DB::Open(options, "/tmp/testdb", &db); ... use the database ... delete db; delete options.filter_policy;
在这个例子中给,使用了BloomFilterPolicy,指定每存在一个key,就增加10个比特位用于过滤,这个值大约将读取操作减少100倍。更大的值能更多减少文件读操作,也会消耗更多存储空间。虽然过滤器有一定存储和计算消耗,但仍然建议经常随机读取,且数据大的应用设置一个过滤器。
如果使用了自定义的比较器,就要保证过滤器和比较器兼容。比如,比较器中忽略了key中最后几个字节,过滤器也要忽略这几个字节,这就需要自定义过滤器:
class CustomFilterPolicy : public leveldb::FilterPolicy { private: FilterPolicy* builtin_policy_; public: CustomFilterPolicy() : builtin_policy_(NewBloomFilterPolicy(10)) {} ~CustomFilterPolicy() { delete builtin_policy_; } const char* Name() const { return "IgnoreTrailingSpacesFilter"; } void CreateFilter(const Slice* keys, int n, std::string* dst) const { // Use builtin bloom filter code after removing trailing spaces std::vector<Slice> trimmed(n); for (int i = 0; i < n; i++) { trimmed[i] = RemoveTrailingSpaces(keys[i]); } return builtin_policy_->CreateFilter(&trimmed[i], n, dst); } };
有些情况下,不用 bloom filter 会更准确高效,例如,你将能被1007整除的存在一起,能被1007除余1的放在一起,能被1007除余2的放在一起…,这就可以自定义过滤器,判断key 被1007整除余几,也是很高效的。总之不用bloom filter的情况我还没遇到过。
leveldb存储数据时会带校验和,但通常不需要,因为可以通过文件系统,RAID等方式验证完整性。意外总会发生,leveldb提供了两种校验和验证方式。
一种方式是在读取操作时指定 ReadOptions::verify_checksums,这个参数为真的话,这一次读取操作里,所有这次从文件中读取的数据都被校验,这个功能默认是关的。第二种操作是在数据库打开时指定 Options::paranoid_checks,这个参数为真的话,当leveldb在操作中发现任何数据损坏,就会返回错误(Google 不抛出异常),这个功能默认也是关的。
当部分数据损坏,程序仍然能够读取没有损坏的数据,如果是在打不开,可以会调用 leveldb::RepairDB 恢复尽可能多的数据。
使用 GetApproximateSizes 函数可以获得一段数据大约占用了多少存储空间。
leveldb::Range ranges[2]; ranges[0] = leveldb::Range("a", "c"); ranges[1] = leveldb::Range("x", "z"); uint64_t sizes[2]; leveldb::Status s = db->GetApproximateSizes(ranges, 2, sizes);
上述例子中,\(size[0]\) 表示 \([a..c)\) 占用的空间,\(size[1]\) 表示 \([x..z)\) 占用的空间。这个数字不准,因为leveldb不光存了key-value数据,还有一些校验,索引,过滤器等,这些内部使用的数据常常是作用于一批key的,不能精确地说某个key占用了多少这些数据所以这个大小是大致数值。其实也挺精确的。
所有文件操作,以及其他系统调用都封装到 leveldb::Env 里面了。见多识广的专家可能希望自己实现一个Env来优化这些调用。例如,有人嫌直接调用系统接口太快了,占用太多IO,想实现个慢点操作IO的leveldb,就会这么做:
class SlowEnv : public leveldb::Env { ... implementation of the Env interface ... }; SlowEnv env; leveldb::Options options; options.env = &env; Status s = leveldb::DB::Open(options, ...);
移植其他平台需要实现 leveldb/port/port.h 中声明的结构和函数,参考 leveldb/port/port_example.h 。除此之外,还需要实现这个平台的 leveldb::Env。这个事我没干过,毕竟厂里的存储需求用Linux都能满足。
By Liao Tonglang.
把当前热点继续串成多页阅读,而不是停在单篇消费。
LevelDB 缓存实现解析:LRU 算法在 Key-Value 数据库中的应用与优化
从零实现 LSM-Tree Compaction:最小堆多路归并迭代器、Level 分层与 Compaction 打分、Tombstone 下推、Version/VersionEdit/MANIFEST 版本管理,以及 Leveled/Size-Tiered/Universal 三种策略的量化对比。从零写一个 LSM-Tree 存储引擎系列第 4 篇。
组装完整 LSM-Tree 存储引擎:DB 接口(Open/Put/Get/Delete/Iterator/Snapshot)、单写多读并发控制、启动恢复,然后用 Rust 重写核心模块,记录 5 个编译器不让我过的故事,最后三方 benchmark 对比。从零写一个 LSM-Tree 存储引擎系列第 5 篇。
从零理解 LSM-Tree 存储引擎的设计哲学:B-Tree 与 LSM-Tree 的本质差异,写放大/读放大/空间放大的三角权衡,以及 WAL、MemTable、SSTable、Compaction、Bloom Filter 各组件的角色与协作关系。从零写一个 LSM-Tree 存储引擎系列第 1 篇。