{kind=link}
【Linux 网络子系统深度拆解】内核网络调优方法论:从基准测试到生产验证
系统化的 Linux 内核网络调优方法论:从基准测试建立性能基线,到 sysctl 参数与内核数据结构的对应关系,再到中断亲和性、NUMA 拓扑、ring buffer、qdisc 的逐层调优,最终通过 A/B 对比验证生产效果。
SYN 是 TCP 三次握手的一部分,开发网络应用时通常不会关注,但它与请求中偶发的长时延 (latency spike) 密切相关,是服务器维护环节中不可忽视的重要部分。如果 SYN 在发送过程中丢包了,通常客户端会在 1s, 3s, 7s, 15s, 31s 后重,这就是长延迟的来源之一。备受游戏公司困扰的 SYN Flood 攻击也是利用了 SYN 的特点。
如下面 TCP 状态图 的上部分 所示,当应用 listen() 之后,就可以接收 SYN 并发送 SYN+ACK,进入 SYN RECEIVED 状态;等待收到 ACK 之后,进入 ESTABLISHED 状态。之后就可以被应用 accept()。
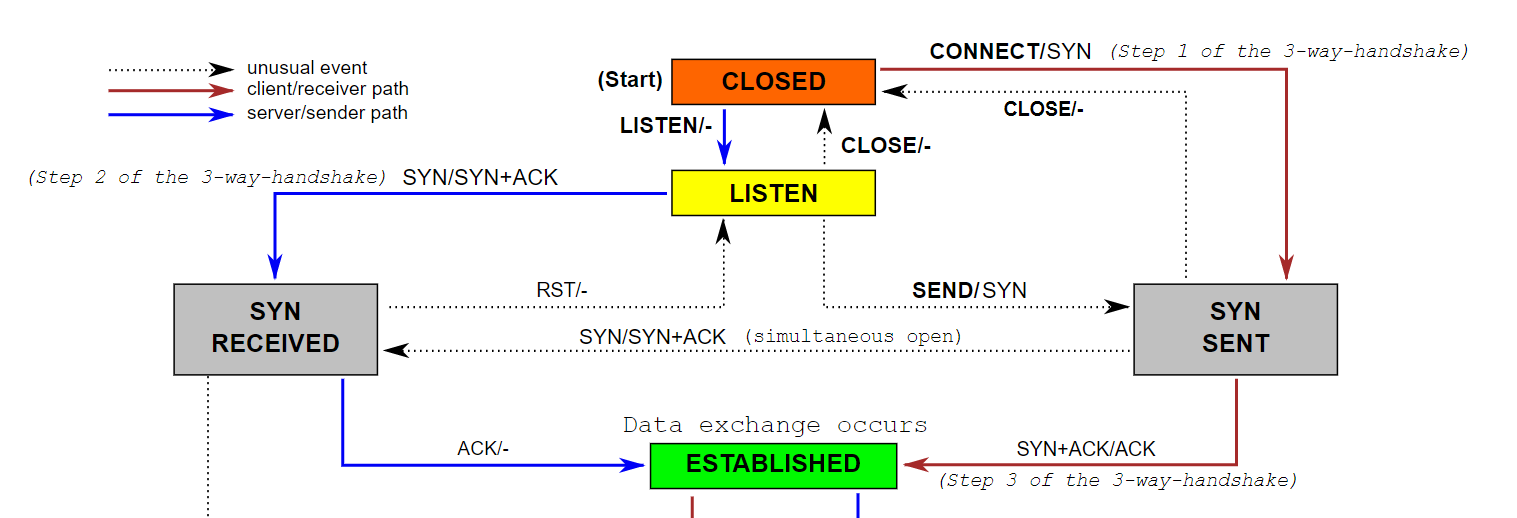
这意味着一个 TCP 连接的建立过程里,有两个等待: 1 是等待 ACK,2 是等待应用 accept()。Linux 使用 2 个队列实现这两次等待, 队列中保存 struct inet_request_sock 结构。我们不考虑特殊情况,如 TCP_SAVED_SYN, TCP_DEFER_ACCEPT, TCP_FAST_OPEN 。
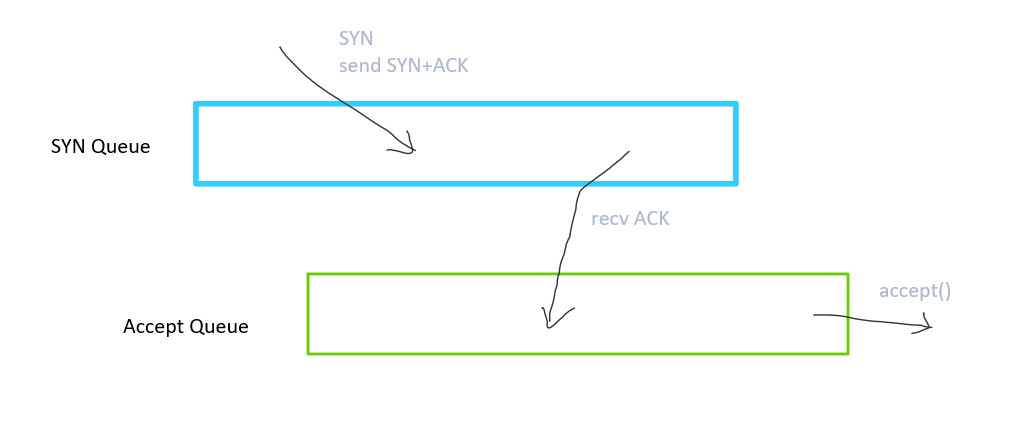
第一个队列是 SYN queue (也叫未完成队列),当收到 SYN 并返回 SYN+ACK 之后,连接会保存在这个队列中,并等待 ACK,连接进入 SYN RECEIVED 状态。等待 ACK
超时的话会重传 net.ipv4.tcp_synack_retries 次。由于 SYN Cookie 的存在,这个队列的长度并不十分重要。
第二个队列是 Accept queue (也叫完成队列),当收到 ACK 以后,连接从 SYN queue
移除,保存到 Accept queue 中,进入 ESTABLISHED 状态,等待应用调用 accept() 。如果队列满了会发送 RST。
SYN Queue 的长度由 /proc/sys/net/ipv4/tcp_max_syn_backlog 控制。 Accept queue
的长度由 listen() 的第二个参数 backlog 限制,并且不能大于
/proc/sys/net/core/somaxconn 。 somaxconn 在 Linux 5.4 之前默认值是 128,5.4
之后改成了 4096。
这个问题经常被提出: backlog 应该设置为多少?
答案是看情况。大多数情况这个参数不重要,Golang 1.11 之前甚至不能改变这个参数。如果新建连接非常频繁,或者设置了 TCP_DEFER_ACCEPT,可以设置得大一些。但设置过大也是不对的,1个 inet_requst_sock 占用 256 字节呢。
有些系统管理员会建议设置一个非常大的 backlog 而且让 net.core.somaxconn
也非常大。这实际上是掩盖了应用程序的问题,如果应用程序一直来不及消费,队列大也没有多少意义,反而会引起客户端的长时延。不如设置一个短的队列,用 RST
尽早告诉客户端出了某些问题,可能需要重连,如果设置了合适的负载均衡器,重连时可能就是好的。
我一般设置 listen(fd, -1) ,然后根据情况修改 somaxconn 的值。
使用下面的命令可以查看某个端口的 SYN Queue 元素数量:
ss -n state syn-recv sport = :80 | wc -l
使用下面的命令可以查看某个端口的 Accept Queue 元素数量,其中 Recv-Q 就是 Accept Queue 元素数量,而 Send-Q 是 backlog 参数。
ss -plnt sport = :80
有几个变量可以查看队列满的次数:
TcpExtTCPReqQFullDoCookies 是 SYN Queue 满而转为 Syn Sookie 的次数。
使用下列命令查看这些变量:
nstat -az TcpExtListenOverflows
根据实际需要调整 somaxconn 即可。
1996 年之前,不停地发送 SYN 可以另服务器 SYN Queue 满从而停止服务,直到 SYN Cookie 出现。这种攻击就是 SYN Flodd,只需要少量的带宽,发送不算太多的报文,就可以让 SYN Queue 满,简单有效:
因为 ACK 的 ack 值就是 SYN+ACK 的 seq 值,可以SYN的哈希值保存到 seq 里,收到 ACK 的时候再验证。这样就不再需要 SYN Queue 了:
+----------+--------+-------------------+ | 6 bits | 2 bits | 24 bits | | t mod 32 | MSS | hash(ip, port, t) | +----------+--------+-------------------+
开启 syn cookie (net.ipv4.tcp_timestamps=1 ,默认开启) 之后,SYN Queue
满时会启用这个功能,用以防范 SYN Flood。比较麻烦的问题就是,这会向网络中发送大量没用的 SYN+ACK。
Linux 4.4 之前,SYN 的处理是很慢的,然后他们把一个内核锁去掉了,现在基本不需要过度担心 SYN Flood 的问题。
By Liao Tonglang.
把当前热点继续串成多页阅读,而不是停在单篇消费。
系统化的 Linux 内核网络调优方法论:从基准测试建立性能基线,到 sysctl 参数与内核数据结构的对应关系,再到中断亲和性、NUMA 拓扑、ring buffer、qdisc 的逐层调优,最终通过 A/B 对比验证生产效果。
tcp_sendmsg 把用户数据拷到 sk_buff 就完事了?远没有。后面还有 Nagle 合并、TSQ 限流、cwnd/rwnd 双窗口门控、RACK-TLP 丢包检测、拥塞状态机五态跳转、sk_pacing_rate 软件限速。本文从 Linux 6.6 内核源码拆解 TCP 数据传输的完整路径——从 send() 到 ACK 处理——以及拥塞控制框架 tcp_congestion_ops 的可插拔架构。
TCP 连接在内核中不只是一个状态机——它是一组精心设计的数据结构和队列。本文从 Linux 6.6 内核源码出发,拆解 TCP 连接建立的 SYN Queue / Accept Queue 二级队列模型、request_sock 半连接对象、tcp_sock 全连接对象、SYN Cookie 无状态防御、TCP Fast Open 零 RTT 机制、inet_timewait_sock 轻量级 TIME_WAIT 实现,以及完整的 TCP 状态机在内核中的真实转换路径。
从 sk_buff 到 XDP,从收包路径到 TC 框架——系统拆解 Linux 内核网络子系统的每一个核心模块。基于 Linux 6.6 LTS 源码,配合 bpftrace/perf 实测追踪。