一致性哈希中的溢出问题:为什么你的集群比你想象的更容易爆满
深入探讨一致性哈希在实际应用中的溢出概率问题,通过交互式可视化展示为什么集群容量规划比你想象的更复杂
一致性哈希是现代分布式系统最常用的算法,它能让数据节点增减变化时,尽可能地保持原来再某个节点上的数据仍然还在那个节点上。最初,一致性哈希被应用 peer-to-peer 网络上,最开始是Chord,后来也被用在 BitTorrent 上。如今,所有的分布式数存储都用了,大概是 Amazon 的 Dynamo 的文章 发布以后,大家纷纷效仿。
假设你提供一个缓存服务,用来保存 key-value 数据,数据量和请求量很大以至于单一服务器不能满足存储要求。所以你设立了 \(n \) 个缓存服务器,用来保存这些 key-value 数据。那么,如何从一个 \(key \) ,快速找到这个 \(key \) 存在哪个服务器上面呢?
显然 \(n \) 个服务器挨个去问不是个好办法。最简单的方法是取 \(key \) 的哈希值:
\[ serverIndex = hash(key) \mod n \]
例如,假设 \(n=4 \),哈希函数 \(hash(key) = atoi(key[3])+100 \) ,那么
| key | hash(key) | hash(key) mod 4 |
|---|---|---|
| key0 | 100 | 0 |
| key1 | 101 | 1 |
| key2 | 102 | 2 |
| key3 | 103 | 3 |
| key4 | 104 | 0 |
| key5 | 105 | 1 |
| key6 | 106 | 2 |
| key7 | 107 | 3 |
因此,服务器和 \(key \) 的分配如下:

现在一个服务器 (serverIndex=1) 要关掉,\(n=3 \) 了,得重新给服务器编号,重新计算每个 \(key \) 在哪个服务器上,然后再把它迁移过去。
| key | hash(key) | hash(key) mod 3 |
|---|---|---|
| key0 | 100 | 0 |
| key1 | 101 | 1 |
| key2 | 102 | 2 |
| key3 | 103 | 0 |
| key4 | 104 | 1 |
| key5 | 105 | 2 |
| key6 | 106 | 0 |
| key7 | 107 | 1 |

可以看到,总共8个 \(key \) 就需要迁移7个,大部分都要迁移,很麻烦。一致性哈希就是要解决这个问题。
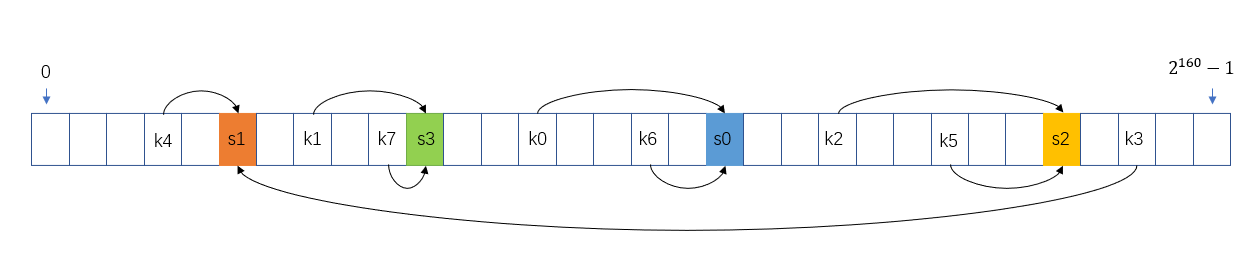
我们用 s0 表示 serverIndex=0 的服务器,s1 表示 severIndex=1 的服务器,以此类推。指定一个哈希函数,比如 SHA-1,它的值域是 \(\left\{x\in N, 0 \leq x \leq 2^{160}-1\right\} \) 。把 s0-s3 哈希后放上数轴上,大致就长这样子:

用 k0 表示 Key0,k1 表示 key1,以此类推,k0-k7 画在数轴上,大概是这样:

一致性哈希的原理,就是把 key 存储在数轴上下一个服务器节点中。例如上图, k1、k7 就保存到 s3,k0、k6 保存到 s0,k3、k4 保存到 s1。可以看到 k3 后面没服务器了,就从0开始往后找到 s1。
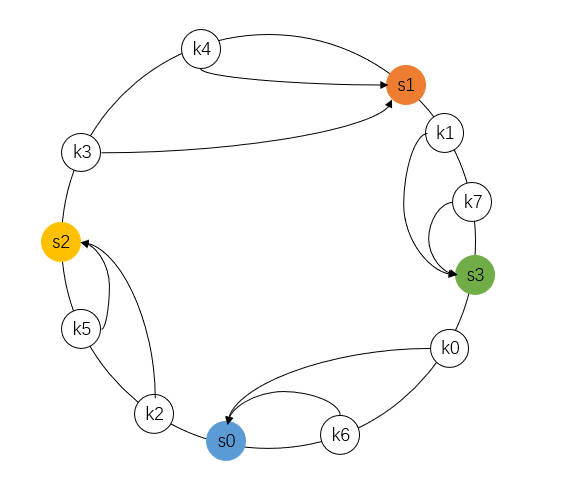
大多文章都把这个数轴画成环,就像下面这样:
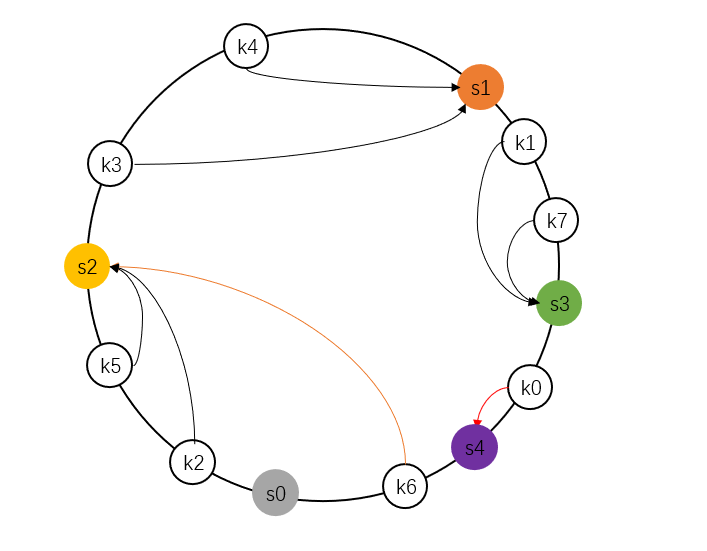
如果要添加一个服务器 s4,那么如下图,只需要迁移 k0 这1个key。

如果要把一个服务器 s0 删掉,如下图,只需要迁移 k6 这 1 个 key。
一致性哈希就是这样,把服务器哈希值放到数轴环上,再把 key 的哈希值放上去,顺时针遇到的第一个服务器就是这个 key 的存储位置。
基本的一致性哈希有两个问题:
如图:
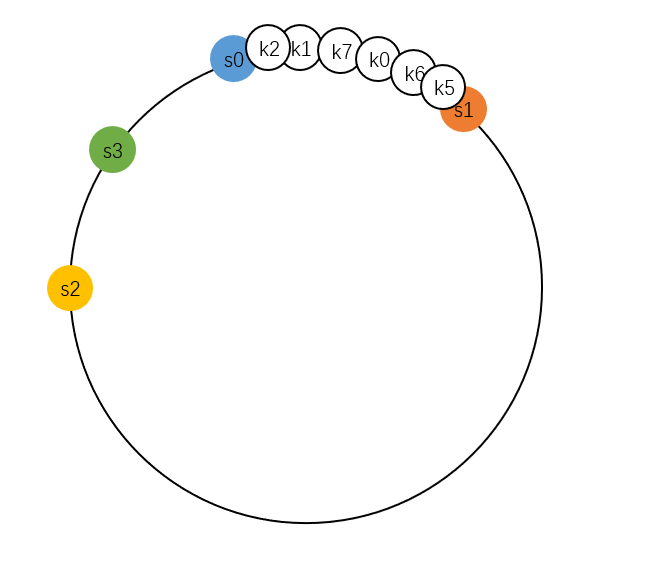
虚拟节点可以解决这个问题。简单地说,就是给服务器起别名,别名的哈希值也放到数轴上,但是这些别名节点,都代表一个服务器。这样,节点数量多,就可以把节点大致均匀分布在数轴环上了。
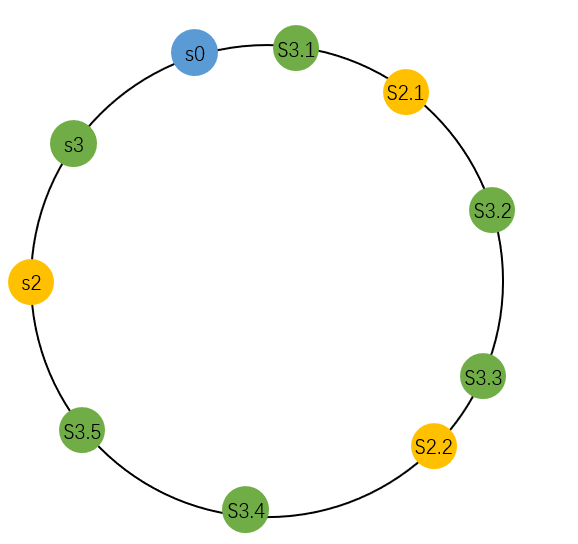
大多数分布式存储系统都要一份数据保存在多个服务器上,例如要保存在3个服务器上,那么,key 存储的节点,就要在数轴上继续向前走,首先遇到的三个代表不同真实服务器的节点就是要存储的位置。
一致性哈希可以解决 Key 重新分布的问题,更容易横向扩展或缩减。用了以后还是有很多需要解决的问题。如一致性如何保证,如何检测系统中服务器故障,如何检测某个服务器数据出错,服务器之间如何通信。要使用它,涉及到的知识依然很多,单也不是不能解决。有现成的计数可以参考:Amazon Dynamo, Redis, Cassandra,BitTable,Markle Tree,SSTable,Bloom filter。具体实现时,相信上述提及的软件和技术都能帮到你。
延伸阅读
By Liao Tonglang.
把当前热点继续串成多页阅读,而不是停在单篇消费。
深入探讨一致性哈希在实际应用中的溢出概率问题,通过交互式可视化展示为什么集群容量规划比你想象的更复杂
蒙特卡洛模拟显示:在 5-20 个节点的常见部署规模下,一致性哈希环的负载均衡效果远不如 Jump Consistent Hash、Rendezvous Hash 等替代方案。附完整模拟数据和选型决策框架。
服务架构演化实践:从单体到微服务,系统扩展性设计与优化历程
深度剖析 SLA "几个9"背后的统计陷阱:独立性假设、级联故障、关联故障如何让你的可用性数字沦为一厢情愿的幻觉