〇、为什么我们要回头看 RNN
到这篇为止,我们已经把 Transformer 之前的 NLP 基础铺了大半:从向量和矩阵 → 可学习函数 → 激活函数与反向传播 → softmax → embedding → 普通神经网络。所有这些机器都准备好之后,一个核心问题浮出水面:怎么处理一个可变长度的序列?
如果刚读完 08.5
神经网络基础,可以把 RNN 理解成一个很直接的改造:普通
MLP 的隐藏表示只在一次前向传播里存在,而 RNN
让隐藏表示沿时间传下去,成为
h_t。这个小改动带来了“记忆”,也带来了后面所有麻烦。
一个句子是变长的:「Hello」是 1 个词,「The quick brown fox jumps over the lazy dog」是 9 个词,一段评论可能是 200 个词。怎么让神经网络处理这种「输入长度不定」的输入?
更根本的:怎么让网络捕捉「序列中位置之间的关系」?「我爱你」和「你爱我」字面上由相同的字组成,但意思相反,原因就在词的顺序。模型必须理解「顺序」这个概念。
在 Transformer 之前,主流答案是 RNN(Recurrent Neural Network,循环神经网络)。从 1980 年代末开始,RNN 统治了序列建模 30 年,催生了 LSTM、GRU、Seq2Seq 等里程碑式的架构。它的工程影响延续至今——Google Translate、Siri、早期 ChatGPT 的前身(GPT-1 之前的 OpenAI 实验),都跟 RNN 有渊源。
但 RNN 有它的根本局限:长程依赖、梯度稳定性、训练并行性。这些问题最终催生了 Transformer。要理解 Transformer 为什么是个突破,必须先理解 RNN 为什么走到了尽头。这就是这一篇的目的。
一、序列建模问题:抽象与符号
1.1 什么是序列
序列就是「有顺序的元素列」:\(x = (x_1, x_2, \ldots, x_T)\),其中 \(T\) 是长度(可变),\(x_t\) 是第 \(t\) 个元素(可以是词、字符、像素、传感器读数)。
序列建模的几类任务:
第一类,序列标注(sequence labeling):给每个元素打标签。例如词性标注:输入「I love cats」,输出「PRON VERB NOUN」。输入和输出长度相同。
第二类,序列分类:给整个序列一个标签。例如情感分析:输入一段评论,输出「正面」或「负面」。输入是序列,输出是单个值。
第三类,序列生成(sequence-to-sequence, seq2seq):输入一个序列,输出另一个序列,长度可能不同。例如机器翻译:输入英文句子,输出中文句子。语音识别、文本摘要也是这一类。
第四类,自回归语言建模:基于历史 \(x_{<t}\) 预测下一个 \(x_t\)。这是后来 GPT 系列的核心任务。
这四类任务表面不同,但都需要一个能「沿序列前进、累积信息」的神经网络。RNN 就是为这个目的设计的。
1.2 为什么前馈网络不够
最朴素的想法:把序列拼成一个长向量,喂进多层感知机(MLP)。这样不行的原因有两点。
第一,长度不固定。MLP 的输入维度是固定的,没法处理变长输入。你可以 padding 到最大长度,但浪费严重,且最大长度需要预先知道。
第二,没有「位置共享」的归纳偏置。同一个词出现在句子开头和句子结尾,应该用同样的方式处理。MLP 把每个位置当作独立特征,不共享参数。这意味着模型必须在每个位置独立学一遍「什么是名词」「什么是动词」,效率极低。
我们需要的是一个网络结构:第一,可以处理变长输入;第二,在不同位置共享参数;第三,能让位置之间的信息相互影响。RNN 满足这三点。
1.3 卷积也是一种解法
除了 RNN,CNN(卷积神经网络,Convolutional Neural Network)也是处理序列的一种经典方案。CNN 最初在图像处理领域大放异彩,它的核心思想是用一个“小滑窗”(也就是卷积核),在数据上平移,专门用来提取局部特征。把这个思想对应到序列数据里,就是 1D 卷积:让卷积核沿着时间轴滑动,每次同时看相邻的几个词,去捕捉诸如“不太好”、“非常棒”这样的局部模式。Kim 2014 的 “Convolutional Neural Networks for Sentence Classification” 就是用 1D-CNN 做文本分类的代表作。
有了上面的概念,就不难理解它的特性了: CNN 的优点:天然并行(因为它不需要像 RNN 那样等上一步的结果,卷积操作可以一次性全部算完)、参数共享(同一个卷积核在整个句子的所有位置复用)。 缺点:感受野(模型一次能看到的输入范围)有限,通常只能捕捉「局部」模式,要想捕捉相隔很远的词语关系(长程依赖)就会很困难,除非你把网络堆叠得非常深。
CNN 在 NLP 里有过一段流行期(2014-2017),但被 RNN 和 Transformer 先后压过。我们这篇主要讲 RNN。
1.4 dilated convolution 与 WaveNet
DeepMind 2016 的 WaveNet 用「扩张卷积」(dilated conv)处理语音波形。每层的卷积核间隔倍增(1, 2, 4, 8, …),让感受野指数增长,能覆盖几千个时间步。
WaveNet 是 CNN 思路的极致:通过精心设计的扩张率,CNN 也能处理超长序列。它在语音合成上击败了 LSTM,证明「CNN 不能处理长序列」是片面的。
但 WaveNet 仍有局限:感受野虽大但仍是固定的,不像 attention 那样能动态选择关注点。这个故事告诉我们,序列建模的核心矛盾不只是「卷积 vs 循环」,更深层是「全局关注 vs 局部归纳」。
1.5 Transformer 是序列建模的第三条路
序列建模有三条路:
第一条,循环(RNN/LSTM/GRU):沿时间逐步累积信息。优点是 \(O(N)\) 内存、灵活;缺点是不能并行、长程依赖难。
第二条,卷积(1D-CNN/WaveNet/ConvS2S):用局部卷积核扫过序列。优点是并行;缺点是感受野有限,长程难。
第三条,注意力(Transformer):每个位置直接关注所有其他位置。优点是 \(O(1)\) 距离、可并行;缺点是 \(O(N^2)\) 复杂度。
每条路都有适用场景。理解 RNN 是理解第一条路的核心,也是看清第三条路如何超越前两条的关键。
二、Vanilla RNN:1990 年的设计
2.1 Elman 1990
最早的现代 RNN 之一是 Elman 1990 的 “Finding Structure in Time”。这篇论文不是数学突破,但是结构上的关键一步:让网络的隐藏层不仅接受当前输入,还接受自己在上一步的输出。
这一改让网络获得了「记忆」:第 \(t\) 步的隐藏状态 \(h_t\) 既依赖当前输入 \(x_t\),也依赖前一步的 \(h_{t-1}\),进而隐含地依赖 \(x_{t-1}, x_{t-2}, \ldots, x_1\) 的全部信息。
Elman 的工作是一个看似简单的修改,但开启了「神经网络记忆」这个研究方向。Jordan 1986 的工作也类似(让输出反馈到隐藏层)。这些早期工作奠定了循环神经网络的基本范式。
2.2 数学定义
Vanilla RNN 的更新方程:
\[ h_t = \tanh(W_h h_{t-1} + W_x x_t + b), \]
\[ y_t = W_y h_t + c. \]
参数:\(W_h \in \mathbb{R}^{d \times d}\)(隐藏到隐藏)、\(W_x \in \mathbb{R}^{d \times m}\)(输入到隐藏,\(m\) 是输入维度)、\(W_y \in \mathbb{R}^{k \times d}\)(隐藏到输出)、\(b, c\) 是偏置。
注意一个关键性质:这套参数在每个时间步都是同一份。\(W_h, W_x, W_y\) 不随 \(t\) 变化。这就是「权重共享」(weight sharing),让 RNN 能处理任意长度的序列——参数量不随长度增长。
2.3 展开形式
把循环结构「展开」沿时间轴画出来,就得到一个像深度前馈网络的图:

左边是折叠写法:一个 RNN cell 把隐藏状态反馈给自己;右边是沿时间轴展开后的写法:同一个 cell 在每个时间步复用,水平箭头携带隐藏状态 \(h_t\),竖直箭头分别表示当前输入 \(x_t\) 和当前步的输出 \(y_t\)。
展开之后 RNN 看起来就是一个「权重共享的深层网络」。深度等于序列长度 \(T\)。这个视角让我们能用反向传播训练它(下一节 BPTT)。
2.4 隐藏状态的含义
\(h_t\) 是 RNN 的「记忆」:它是整个 \(x_1, \ldots, x_t\) 的一个固定大小的总结。理论上 \(h_t\) 可以包含任意多的历史信息,但实际上 \(d\) 维向量的容量是有限的,长序列里早期的信息会被新信息覆盖。
这是 RNN 后来面临的根本难题:固定容量的隐藏状态,怎么承载长序列的全部信息?答案是「不能完全承载」,只能压缩、有损地保留最重要的部分。
2.5 一个具体例子
考虑序列「The cat sat on the」。Vanilla RNN 处理这个序列:
- \(h_0\) 初始化为零或学习参数。
- \(h_1 = \tanh(W_h h_0 + W_x \mathbf{e}_{\text{the}} + b)\)。
- \(h_2 = \tanh(W_h h_1 + W_x \mathbf{e}_{\text{cat}} + b)\)。
- …
- \(h_5 = \tanh(W_h h_4 + W_x \mathbf{e}_{\text{the}} + b)\)。
最终 \(h_5\) 编码了整个 prefix 的信息。如果做语言建模任务,输出层 \(y_5 = W_y h_5\) 给出下一个词的 logits,应该把概率集中在「mat、chair、roof」等可坐物体上。
2.6 RNN 的 PyTorch 实现
import torch
import torch.nn as nn
class VanillaRNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super().__init__()
self.W_h = nn.Linear(hidden_dim, hidden_dim, bias=False)
self.W_x = nn.Linear(input_dim, hidden_dim, bias=True)
self.W_y = nn.Linear(hidden_dim, output_dim)
def forward(self, x_seq, h0=None):
# x_seq: (T, batch, input_dim)
T, B, _ = x_seq.shape
h = h0 if h0 is not None else torch.zeros(B, self.W_h.out_features)
ys = []
for t in range(T):
h = torch.tanh(self.W_h(h) + self.W_x(x_seq[t]))
ys.append(self.W_y(h))
return torch.stack(ys), h这是教学代码。生产代码用 nn.RNN,里面是 CUDA
优化的实现。
2.7 初始隐藏状态与 batch_first 陷阱
隐藏状态 \(h_0\) 怎么定? 常见选择:
- 零向量:最简单,但训练初期会让所有序列从同一起点开始,可能不利于多样性。
- 可学习参数:把 \(h_0\) 当成参数,反向传播时也优化它。
- 根据任务设定:例如机器翻译里,encoder 的最终隐藏状态作为 decoder 的 \(h_0\)。
经验上零向量已经够用,差异通常很小。
batch_first
陷阱:在上述教学代码中,输入形状是
(T, B, dim)。这是 PyTorch RNN
类默认的行为(batch_first=False),不仅是初学者,也是许多老手常踩的坑。
为什么如此反直觉?因为在底层循环实现中,沿时间轴 \(T\) 遍历时,\(x_t\) 的形状必须是
(B, dim)。如果输入是
(T, B, dim),在内存里切片取 \(x_t\) 更连续、更高效。
如果你希望输入符合其他网络(如 CNN、全连接层)习惯的
(B, T, dim) 形状,必须在 nn.RNN 或
nn.LSTM 中显式指定
batch_first=True。
2.8 单向 vs 双向 RNN
Vanilla RNN 是「单向」的:\(h_t\) 只依赖 \(x_1, \ldots, x_t\)(过去)。如果任务允许用未来信息(比如词性标注,可以看后文),可以用「双向 RNN」(BiRNN,Schuster 1997):
正向 RNN:\(\overrightarrow{h}_t = \tanh(W \overrightarrow{h}_{t-1} + U x_t)\),从左到右。
反向 RNN:\(\overleftarrow{h}_t = \tanh(W' \overleftarrow{h}_{t+1} + U' x_t)\),从右到左。
最终 \(h_t = [\overrightarrow{h}_t; \overleftarrow{h}_t]\)。
双向 RNN 在很多任务上效果显著好——「我把书还给图书馆」里,「书」是名词还是动词,看后面的「还给」就能确定。但在自回归生成(不能看未来)任务里只能用单向。这是 BERT vs GPT 的早期版本。
2.9 RNN 与 Markov 假设的区别
经典语言模型(n-gram)是 Markov 模型:当前词只依赖前 \(n-1\) 个词。这种「有限历史」假设是为了让模型可估计(n-gram 概率可以由计数估出),但严格地损失了长程信息。
RNN 在数学上是「无限历史」的:\(h_t\) 理论上能编码 \(x_1, \ldots, x_t\) 全部信息。这是 RNN 相比 n-gram 的根本进步——它可以原则上捕捉任意长度的依赖。
但「理论上可以」和「实际上可学习」不同。Vanilla RNN 因为梯度消失问题,实际能用的依赖距离很短(10-20 步左右)。LSTM 把这个范围推到几百步。Transformer 之后才能稳定处理几千甚至几十万步。
2.10 为什么用 tanh
Vanilla RNN 用 tanh 作激活函数,不用 ReLU。原因:tanh 输出在 \([-1, 1]\),让 hidden state 范数受控;ReLU 的输出可以无界,循环几次会让 hidden state 范数指数爆炸。
但 tanh 的代价是「饱和区域梯度为 0」(\(\tanh' = 1 - \tanh^2\),当 \(|x|\) 大时趋零)。这是梯度消失的一个来源。门控 RNN(LSTM/GRU)用 sigmoid + tanh 组合,在不同地方各司其职。
三、BPTT:反向传播穿越时间
3.1 把 RNN 当深网络
RNN 的训练就是普通的反向传播,只是要把展开后的图当作一个深度等于序列长度的前馈网络。这种「沿时间反向传播」的版本叫 BPTT(Backpropagation Through Time)。
设损失 \(\mathcal{L} = \sum_t \mathcal{L}_t\)(每步都有损失)。计算 \(\partial \mathcal{L} / \partial W_h\):
\[ \frac{\partial \mathcal{L}}{\partial W_h} = \sum_t \frac{\partial \mathcal{L}_t}{\partial W_h}. \]
而 \(\partial \mathcal{L}_t / \partial W_h\) 需要把梯度从 \(\mathcal{L}_t\) 反传到所有 \(h_s, s \le t\)(因为 \(h_t\) 经过 \(W_h\) 依赖 \(h_{t-1}\),\(h_{t-1}\) 又依赖 \(h_{t-2}\),等等)。
3.2 链式法则展开
具体地,对某个 \(\mathcal{L}_t\):
\[ \frac{\partial \mathcal{L}_t}{\partial h_t} \cdot \frac{\partial h_t}{\partial h_{t-1}} \cdot \frac{\partial h_{t-1}}{\partial h_{t-2}} \cdots \frac{\partial h_1}{\partial W_h}. \]
中间所有的 \(\partial h_t / \partial h_{t-1}\) 是雅可比矩阵。每一步雅可比的形式:
\[ \frac{\partial h_t}{\partial h_{t-1}} = \mathrm{diag}(1 - h_t^2) \cdot W_h. \]
(用了 \(\tanh' = 1 - \tanh^2\)。)
3.3 梯度的连乘
把上面的链式法则汇总一下:
\[ \frac{\partial \mathcal{L}_t}{\partial h_s} = \frac{\partial \mathcal{L}_t}{\partial h_t} \prod_{k=s+1}^{t} \frac{\partial h_k}{\partial h_{k-1}}. \]
这是一个雅可比矩阵的连乘,长度等于 \(t - s\)。如果 \(t - s\) 很大(比如句子有 100 个词,要把第 100 步的损失反传到第 1 步),这个连乘有 100 个矩阵相乘。
矩阵连乘的「奇异值」有一个直观图景:每次乘 \(W_h\) 大致让向量长度乘以 \(W_h\) 的最大奇异值 \(\sigma_{\max}\)。如果 \(\sigma_{\max} > 1\),长度指数爆炸;如果 \(\sigma_{\max} < 1\),长度指数衰减。这就是后面要讲的「梯度爆炸 / 消失」。
3.4 BPTT 的内存开销
BPTT 训练需要把 \(h_0, h_1, \ldots, h_T\) 全部保存(前向传播时缓存),反向传播时才能算梯度。内存复杂度 \(O(T)\)。
对长序列(几千、几万 token),这内存开销很大。常见的 mitigation 是 truncated BPTT:把序列切成短段(比如 35 个 token 一段),每段单独反传,段之间只传隐藏状态不传梯度。这降低内存但也限制了梯度的「视野」——超过段长的依赖学不到。
第 32 篇 gradient checkpointing 会回到这个话题。
3.5 BPTT 的并行性问题
注意一个根本问题:BPTT 是严格顺序的。\(h_t\) 依赖 \(h_{t-1}\),所以前向传播必须一步一步算,无法并行。同样反向传播也无法并行。
这意味着无论 GPU 多强,RNN 训练长度 \(T\) 的序列至少需要 \(T\) 个时序步骤。这是 RNN 训练慢的核心原因,也是后来 Transformer 「全位置并行」之所以是革命性突破的根源。
我们在第 10 篇会展开「RNN 的根本局限」,并行性是其中之一。
3.6 BPTT 的实现细节
PyTorch 的 BPTT 是「自动微分」的:你定义 forward 函数(带
for 循环),框架自动构建计算图,调用
loss.backward() 时自动反向传播。
但有一个常见 pitfall:如果你把 RNN 的 hidden state 在
batch 之间传递(continuation BPTT),需要
h.detach(),否则梯度会反传到上一个
batch,内存爆炸。这是 PyTorch RNN 的经典陷阱。
h = torch.zeros(B, hidden_dim)
for batch in dataloader:
out, h = rnn(batch, h)
loss = criterion(out, target)
loss.backward()
h = h.detach() # 关键!切断梯度流
optimizer.step()四、梯度消失与梯度爆炸
4.1 现象描述
理论上 RNN 应该能捕捉任意长度的依赖。实际上 Vanilla RNN 训长序列时常出问题:
梯度爆炸:训练 loss 突然变成 NaN。原因是某些梯度连乘项超过 1,导致总梯度指数级增大,超出浮点数表示范围。
梯度消失:长程依赖学不到。模型记不住几十步之前的信息,例如句子结构、长距离的代词指代。
这两个问题都源于 BPTT 中的雅可比连乘。
4.2 数学分析
回顾 \(\partial h_t / \partial h_{t-1} = \mathrm{diag}(1 - h_t^2) W_h\)。把它简化为 \(W_h\) 乘一个对角矩阵。\(\tanh\) 的导数 \(1 - \tanh^2\) 在 0 处最大为 1,在 \(\pm \infty\) 处为 0。
如果 \(W_h\) 的最大奇异值 \(> 1\),连乘 \(T\) 步后向量长度大约 \(\sigma^T\),指数爆炸。如果 \(\sigma < 1\),长度 \(\sigma^T \to 0\),梯度消失。
只有当 \(\sigma \approx 1\) 时梯度才能稳定传递。但精确的 \(\sigma = 1\) 是不稳定的——训练中权重稍微偏离一点就走向爆炸或消失之一。
Bengio 1994 的 “Learning Long-Term Dependencies with Gradient Descent is Difficult” 系统地分析了这个问题。它的结论:Vanilla RNN 用梯度下降训练长程依赖在数学上是「困难的」,不只是工程上的难。
4.3 梯度爆炸:gradient clipping
爆炸比消失好治:用「梯度裁剪」(gradient clipping)。当梯度范数超过阈值 \(\tau\) 时,按比例缩小到 \(\tau\):
\[ g \leftarrow g \cdot \min(1, \tau / \|g\|). \]
Pascanu 2013 提出这种方法。它简单粗暴但极其有效——LSTM 训练里几乎是必备 trick。\(\tau\) 典型取 1.0 或 5.0。
实际效果:偶尔出现的大梯度被 clip 掉,训练不再动辄 NaN。代价是「真正大梯度的方向信息」被部分丢失,但实证上影响很小。
4.4 梯度消失:更难治
梯度消失比爆炸难得多。Clipping 救不了——它处理「过大」,对「过小」无能为力。
减缓梯度消失的几种方向:
第一,初始化技巧:把 \(W_h\) 初始化为正交矩阵(奇异值都是 1),让初始连乘稳定。但训练几步之后权重就会偏离正交。
第二,激活函数选择:ReLU 替代 tanh,导数在正区间是 1,不衰减。但负区间梯度为 0,又有「死神经元」问题。
第三,架构改变:引入「跳跃连接」或「门控机制」让梯度有「捷径」。这导向了 LSTM 和 GRU。
LSTM 的核心创新就是为了解决梯度消失。它的方案叫「constant error carousel」(CEC)——梯度在 cell state 上几乎不衰减地传递。
4.5 IRNN 与正交 RNN
Le 2015 的 IRNN(Identity RNN)尝试用很简单的修改解决梯度问题:把 \(W_h\) 初始化为单位矩阵 \(I\),激活函数用 ReLU。这样初始时 \(h_t = h_{t-1} + W_x x_t\),梯度直接传递不衰减。
IRNN 在某些任务上能匹配 LSTM 效果,但训练不稳定,超参敏感。它的存在告诉我们:RNN 的关键是「初始化 + 架构」,不只是「门控」。
正交 RNN(Arjovsky 2016 的 uRNN, unitary RNN)更激进:约束 \(W_h\) 始终是酉矩阵(unitary),保证奇异值都为 1。这在数学上漂亮,但实现复杂、训练慢,没成为主流。
4.6 探究 LSTM 的成功
「为什么 LSTM 解决了梯度消失」这个问题在 2015-2018 年有大量分析。简化版的解释:cell state 路径上的更新是加法(\(C_t = f_t \odot C_{t-1} + i_t \odot g_t\)),不是乘法。加法不会让梯度指数衰减或爆炸。
更深入的分析(Le 2015、Saxe 2014、Pascanu 2013)从动力系统、表示理论等不同角度研究 LSTM。共识是:LSTM 不是「一个 trick 解决梯度消失」,而是多种机制(cell state、门控、加法更新、输入饱和)的组合,每一项都对梯度稳定性有贡献。
4.7 Truncated BPTT
实际训练 RNN 时,序列可能极长(一个文档几万个 token)。完整 BPTT 内存爆炸。Truncated BPTT 是解决方案:把序列切成 \(T_{trunc}\)(如 35)的块,每块独立做 BPTT。
但 Truncated BPTT 有副作用:模型只能学到 \(T_{trunc}\) 范围内的依赖,更长的依赖被切断。所以 PennTreebank 等语言模型实验里 \(T_{trunc}\) 的选取是个 hyperparameter。
更精巧的做法是「stateful 训练」:跨块之间保留 hidden state(detach 梯度但保留数值),让 forward 看到长上下文,backward 只到 \(T_{trunc}\)。这是 PyTorch RNN 训练的标准做法。
4.8 梯度消失的可视化
如果你画出训练 RNN 时各层的梯度范数 \(\|\nabla_{h_t} L\|\),典型情况是:靠近输出的 \(t\) 梯度大,离输出远的 \(t\) 梯度指数衰减。这就是梯度消失的可视化形态。
LSTM 的同样图会平坦得多——cell state 让梯度沿时间几乎不衰减。这种可视化是诊断 RNN 训练问题的常用手段。
五、LSTM:长短时记忆
5.1 Hochreiter & Schmidhuber 1997
LSTM(Long Short-Term Memory)由 Sepp Hochreiter 和 Jürgen Schmidhuber 在 1997 年提出。Hochreiter 当时的硕士论文(1991 年)就已经识别了 RNN 的梯度消失问题,LSTM 是他们解决方案的最终形态。
LSTM 在 1997 发表后头几年没有引起广泛注意——那时候神经网络整个领域都不热。直到 2010 年代深度学习复兴,LSTM 才被「重新发现」并成为 NLP、语音、机器翻译的主流。
5.2 核心思想:cell state + 三门
LSTM 在 Vanilla RNN 上加了一条「专门用来传递长期记忆的通道」:cell state \(C_t\)。\(C_t\) 的更新主要是加法(不是乘法),所以梯度沿 \(C_t\) 传时几乎不衰减。
控制 \(C_t\) 的有三个「门」:forget gate、input gate、output gate。每个门是一个 sigmoid,输出 0 到 1 之间的向量,表示「让多少信息通过」。
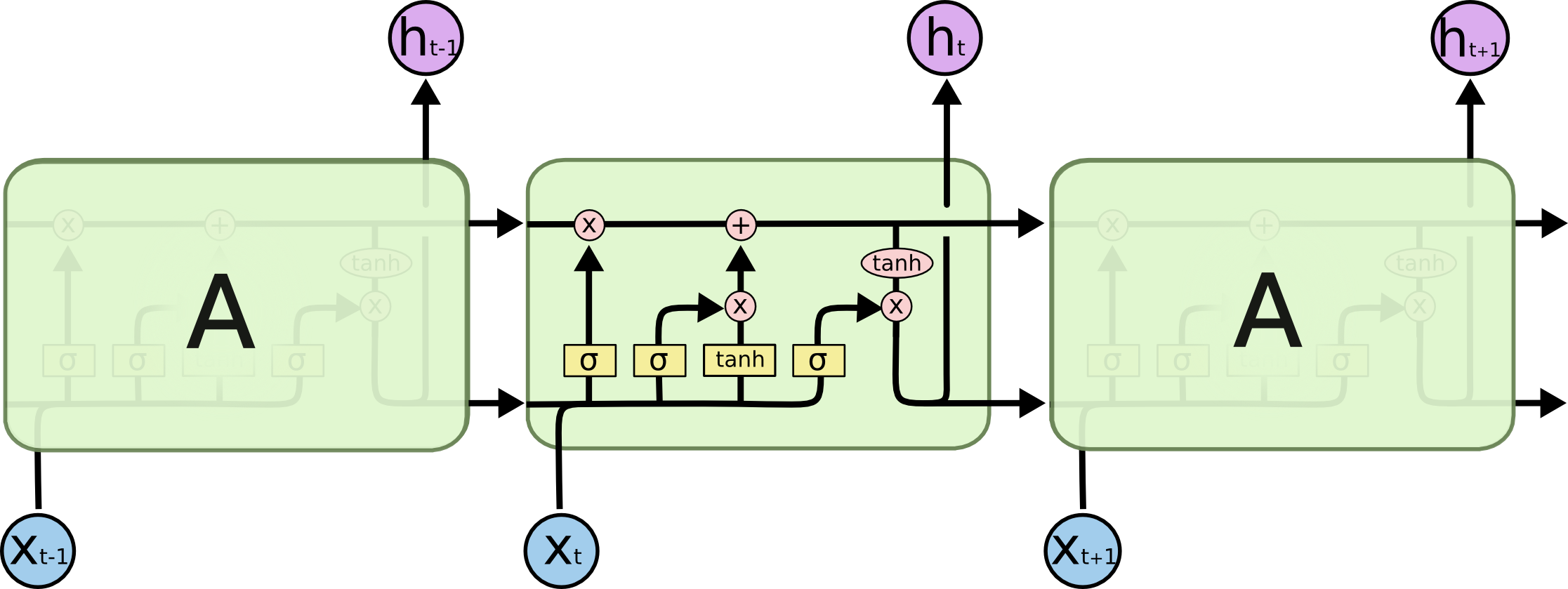 图源:Christopher Olah 的博客《Understanding LSTM
Networks》
图源:Christopher Olah 的博客《Understanding LSTM
Networks》
5.3 数学公式
LSTM 的完整更新:
\[ \begin{aligned} f_t &= \sigma(W_f [h_{t-1}, x_t] + b_f) \quad \text{forget gate} \\ i_t &= \sigma(W_i [h_{t-1}, x_t] + b_i) \quad \text{input gate} \\ g_t &= \tanh(W_g [h_{t-1}, x_t] + b_g) \quad \text{candidate cell} \\ C_t &= f_t \odot C_{t-1} + i_t \odot g_t \quad \text{update cell} \\ o_t &= \sigma(W_o [h_{t-1}, x_t] + b_o) \quad \text{output gate} \\ h_t &= o_t \odot \tanh(C_t) \quad \text{hidden state} \end{aligned} \]
\(\odot\) 是逐元素相乘(element-wise)。\([h_{t-1}, x_t]\) 是拼接。
5.4 三个门的直觉
forget gate \(f_t\):决定 \(C_{t-1}\) 的哪些维度要「忘记」(乘以接近 0),哪些要保留(乘以接近 1)。如果 \(f_t \approx 1\),cell state 几乎不变;如果 \(f_t \approx 0\),cell state 被清空。
input gate \(i_t\) 和 candidate cell \(g_t\):决定要往 \(C_t\) 里「写入」什么新信息。\(g_t\) 是写入的内容,\(i_t\) 是写入的强度。
output gate \(o_t\):决定要从 \(C_t\) 里「读出」什么作为隐藏状态 \(h_t\)。这给了 LSTM 一种「内部记忆 vs 外部输出」的分离——cell state 可以保留某些信息但不立即输出。
这三个门让 LSTM 能学到非常灵活的记忆策略:「这个信息要长期记住」「那个信息只是临时的」「现在要输出某种特征」。
5.5 为什么解决梯度消失
回到 BPTT。看 \(C_t\) 的反向传播:
\[ \frac{\partial C_t}{\partial C_{t-1}} = f_t. \]
如果 forget gate \(f_t \approx 1\)(学到「保留」),那 \(\partial C_t / \partial C_{t-1} \approx 1\),梯度几乎不衰减地传递——「constant error carousel」。
这是 LSTM 的核心:cell state 路径上的梯度由门控决定衰减程度,而不是由权重矩阵的奇异值。如果门学会「保留」,长程梯度就能传递。
实证上 LSTM 能学到几百步前的依赖,这是 Vanilla RNN 做不到的。
5.6 LSTM 的变体
原始 LSTM 之后有很多变体:
- peephole connections(Gers 2000):让门也看 cell state,不只是 hidden state。
- coupled forget and input gates:\(i_t = 1 - f_t\),节省参数。
- LSTM with projection:cell 和 hidden 维度不同。
这些变体在大规模实验里效果差异不大(Greff 2017 的 “LSTM: A Search Space Odyssey” 系统比较了它们)。原始 LSTM 已经很好。
5.7 LSTM 的工程实现
PyTorch 的 nn.LSTM
是最常用的实现。一个标准用法:
import torch.nn as nn
lstm = nn.LSTM(input_size=128, hidden_size=256, num_layers=2, batch_first=True)
x = torch.randn(32, 50, 128) # batch=32, seq_len=50, input_dim=128
output, (h_n, c_n) = lstm(x)
# output: (32, 50, 256) - 每个时间步的 hidden
# h_n: (2, 32, 256) - 最后一步每层的 hidden
# c_n: (2, 32, 256) - 最后一步每层的 cellnum_layers=2 表示 stacked
LSTM,两层叠加。第一层的输出作为第二层的输入。
CuDNN 的 LSTM 实现把整个 forward 写成一个 CUDA kernel,避免 Python 循环开销。这是 LSTM 在 GPU 上能跑得飞快的关键。
5.8 LSTM 的应用历史
2014-2017 年是 LSTM 的黄金期:
- 机器翻译:Sutskever 2014 的 Seq2Seq、Bahdanau 2014 的 attention 都基于 LSTM。
- 语音识别:DeepSpeech、Listen Attend Spell 都用 LSTM。
- 语言模型:AWD-LSTM(Merity 2017)一度是语言建模 SOTA。
- 图像描述:Show and Tell(Vinyals 2015)用 CNN + LSTM。
直到 Transformer(2017)出现,LSTM 才逐步退场。
5.9 LSTM 的训练时间
LSTM 训练慢是出了名的。一个 8 层 LSTM 的 NMT 模型在 8 张 V100 上要训练几天到几周。原因有二:第一,时间步串行,无法并行;第二,每步内部有 4 套矩阵乘法(4 个门),运算密集。
GNMT 论文里花了大量篇幅讨论训练优化:模型并行、数据并行、quantized inference 等。这反映 RNN 时代的工程现实——大规模 LSTM 训练是一个巨大的系统工程问题。
5.10 LSTM 的解释性
LSTM 的隐藏状态有时可以「看出来」一些语义。Karpathy、Johnson、Fei-Fei 2015 的 “Visualizing and Understanding Recurrent Networks” 找到了一些可解释的 LSTM 神经元——比如某个 cell 维度专门追踪「是否在引号内」、另一个追踪「行的位置」。
这种「单细胞解释」让 LSTM 一度被认为比 Transformer 更可解释。但后续研究发现 Transformer 也有类似的「概念神经元」,可解释性不是 RNN 的专利。
5.11 LSTM 的失败模式
LSTM 不是万能的。常见失败模式:
第一,超长依赖(>1000 步)失效:cell state 虽然能保留信息,但实际中 LSTM 学到的有效记忆长度通常在几百步。再长就力不从心。
第二,对位置不敏感:LSTM 难以学到「第 100 个 token 和第 1 个 token 的关系」这种依赖于「绝对位置」的模式,除非显式给位置编码。
第三,对扰动敏感:LSTM 的 hidden 是动力系统的轨迹,小扰动会沿时间累积放大。这导致 LSTM 在对抗样本面前更脆弱。
理解这些失败模式让你知道什么时候不该用 LSTM,应该考虑 Transformer 或其他架构。
5.12 LSTM 在 RL 中的角色
强化学习里 LSTM 是经典选择。Atari、StarCraft、Dota 等环境的 agent 经常用 LSTM 处理「部分可观察 MDP」——把过去的观察聚合到 hidden state 里,让 agent 有「记忆」。
OpenAI 的 OpenAI Five(Dota 2)和 DeepMind 的 AlphaStar(StarCraft 2)都用 LSTM 作为核心模块。Transformer 在 RL 里也开始流行(Decision Transformer 等),但 LSTM 仍是工程上的稳妥选择。
六、GRU:简化版的 LSTM
6.1 Cho 2014
GRU(Gated Recurrent Unit)由 Cho 等人 2014 年提出,目的是简化 LSTM——LSTM 三个门 + cell state 太复杂,GRU 只用两个门,没有显式 cell state。
 图源:Christopher Olah 的博客《Understanding LSTM
Networks》
图源:Christopher Olah 的博客《Understanding LSTM
Networks》
GRU 公式:
\[ \begin{aligned} z_t &= \sigma(W_z [h_{t-1}, x_t]) \quad \text{update gate} \\ r_t &= \sigma(W_r [h_{t-1}, x_t]) \quad \text{reset gate} \\ \tilde{h}_t &= \tanh(W [r_t \odot h_{t-1}, x_t]) \\ h_t &= (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t \end{aligned} \]
6.2 LSTM vs GRU
实证比较(Chung 2014, Greff 2017):两者效果差不多。LSTM 在某些任务上稍好,GRU 在某些任务上稍好,没有压倒性优势。
GRU 的优势是参数少(约 LSTM 的 75%)、训练快。LSTM 的优势是更灵活(有独立的 cell state)。
实际选择常常是工程驱动的:参数预算紧张用 GRU,预算充足用 LSTM。
6.3 门控的统一视角
LSTM 和 GRU 都属于「门控 RNN」(gated RNN)。它们的共同思想:用学习的门控来决定信息的流入、保留、流出。这种思路后来在很多架构里反复出现:
- Highway Network(Srivastava 2015):在前馈网络里加门控,跨层信息直接传递。
- ResNet:跳跃连接,可以看作「forget gate=1」的特例。
- Transformer:虽然不用门控,但 attention 的 softmax 权重某种意义上也是「软门控」。
「门控」是深度学习里的一个核心 idea,LSTM 是它最早最成功的实现。
6.4 门控的代价
门控的代价是参数翻倍——LSTM 参数量是 Vanilla RNN 的 4 倍(forget、input、output、candidate 各一组),GRU 是 3 倍。
这意味着同样隐藏维度下,LSTM/GRU 的参数显著多于 Vanilla RNN。要公平比较时,应该比较「相同参数量下的效果」,而不是「相同 hidden_dim 下」。
6.5 GRU 的 reset gate 直觉
GRU 的 reset gate \(r_t\) 控制「在计算候选 \(\tilde{h}_t\) 时使用多少上一步的 \(h_{t-1}\)」。如果 \(r_t \approx 0\),候选 hidden 几乎只看当前输入;如果 \(r_t \approx 1\),候选 hidden 充分使用历史。
这种「重置」机制让 GRU 能在序列中「重新开始」——遇到新主题时把 hidden 清空。LSTM 的 forget gate 也类似,但 GRU 把它和 update gate 耦合到同一公式里,更紧凑。
6.6 update gate 的「凸组合」
GRU 的 hidden 更新公式 \(h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t\) 是一个凸组合:在「保留」和「更新」之间做软切换。\(z_t\) 是切换权重。
这种凸组合让 hidden 范数受控(不会爆炸),并且梯度能直接通过 \((1-z_t)\) 这条 identity-like 路径传递。在数学上 GRU 比 LSTM 简洁得多。
6.7 LSTM vs GRU 在长序列上的差异
实证发现:极长序列(几千步)上 LSTM 略好于 GRU。可能因为 LSTM 的独立 cell state 提供了更纯粹的「梯度高速公路」。但短序列(几十到几百步)上两者无差异。
工业实践常用 GRU(参数少、训练快),研究里常用 LSTM(更经典、对比基线)。这种历史惯性比理论原则更影响实际选择。
七、Seq2Seq:序列到序列的范式
7.1 Sutskever 2014
2014 年,Ilya Sutskever(后来 OpenAI 联合创始人)等人在 “Sequence to Sequence Learning with Neural Networks” 里提出了 Seq2Seq 框架。这是把 RNN 用于「输入序列 → 输出序列」任务的标准模型。
核心思想:用两个 LSTM。一个叫 encoder,读输入序列,把它压缩成一个固定大小的「context vector」\(c\);另一个叫 decoder,从 \(c\) 出发生成输出序列。

7.2 Encoder
Encoder 是一个 LSTM,读输入 \(x = (x_1, \ldots, x_T)\):
\[ h_t = \mathrm{LSTM}(h_{t-1}, x_t). \]
Encoder 的最终隐藏状态 \(h_T\)(或 cell state \(C_T\))作为 context \(c\)。它是输入序列的「概要」。
注意:Sutskever 2014 的一个重要工程 trick 是反向喂入输入——把句子从右到左喂给 encoder。这让 decoder 第一步能直接看到原句的开头(在 context 里更新鲜),实证显著提升效果。这是 RNN 时代典型的「heuristic engineering」。
7.3 Decoder
Decoder 也是一个 LSTM,从 \(c\) 开始生成:
\[ s_t = \mathrm{LSTM}(s_{t-1}, y_{t-1}, c), \]
\[ P(y_t | y_{<t}, x) = \mathrm{softmax}(W s_t). \]
第一步 \(s_0 = c\);第
\(t\) 步把上一步生成的词
\(y_{t-1}\)
喂入。生成停止于特殊 token <EOS>。
7.4 Teacher Forcing
训练时有一个关键技巧叫 teacher forcing:第 \(t\) 步的输入不是模型生成的 \(\hat{y}_{t-1}\),而是真实的 \(y_{t-1}\)(从训练集来)。这让训练稳定(不会因为前期错误累积导致后期完全跑偏),但和推理时的「用模型自己生成的词」有 distribution shift。
这种 train-test 不一致问题叫 “exposure bias”。后来一系列工作(scheduled sampling, professor forcing 等)尝试缓解,但没完全解决。Transformer 时代仍然存在这个问题。
7.5 Seq2Seq 的应用
Seq2Seq 几乎可以套用到所有「输入序列 → 输出序列」的任务:
- 机器翻译:源语言 → 目标语言。
- 文本摘要:长文档 → 短摘要。
- 对话:用户 utterance → 系统回复。
- 语音识别:音频帧 → 文字。
- 代码生成:自然语言描述 → 代码。
这是一个极其通用的框架。它的影响延续到 Transformer 时代——T5、BART 等模型都还是 encoder-decoder 结构。
7.6 Seq2Seq 的局限:context bottleneck
Seq2Seq 有一个明显的瓶颈:所有输入信息要压进一个固定大小的 context 向量 \(c\)。
短句子还行,长句子(几十词以上)就不够了——一个 1024 维向量装不下全部信息。Bahdanau 2014 实测发现:纯 Seq2Seq 在长句翻译上明显退化。
这个 bottleneck 直接催生了 attention 机制。下一节展开。
7.7 Bahdanau 2014:attention 的引入
Bahdanau 等 2014 年在 “Neural Machine Translation by Jointly Learning to Align and Translate” 里提出:让 decoder 不再只依赖一个固定 context,而是在每一步动态地「关注」encoder 的所有隐藏状态。
具体地,decoder 在第 \(t\) 步计算一个 attention 分布:
\[ \alpha_{ti} = \mathrm{softmax}_i(\mathrm{score}(s_{t-1}, h_i)), \]
\[ c_t = \sum_i \alpha_{ti} h_i. \]
这样每一步的 context \(c_t\) 都不同,根据当前 decoder state 动态调整。长句子也能精确「对齐」到源句的相关部分。
这是 attention 机制的开端。从这里到 Transformer 还有 3 年时间,但思想已经在了。详细的 attention 演化会在第 11、12 篇展开。
7.8 Luong 2015:attention 变体
Luong 等 2015 年研究了 attention 的不同 score 函数:
- dot:\(\mathrm{score}(s, h) = s^\top h\)。最简单,要求 \(s, h\) 维度相同。
- general:\(\mathrm{score}(s, h) = s^\top W h\)。加一个变换矩阵。
- concat(Bahdanau 用的):\(\mathrm{score}(s, h) = v^\top \tanh(W [s; h])\)。最一般但参数多。
Luong 的 paper 比较了这些变体,发现 dot 在很多任务上够用且最快。这预示了 Transformer 的 dot-product attention——其实是 attention 演化的自然终点。
7.9 attention 之前的对齐尝试
在 Bahdanau 之前,统计机器翻译已经有 IBM 模型 1-5 等「对齐模型」。这些模型显式估计「源句词 ↔︎ 目标句词」的对齐概率,比如 IBM Model 1 假设每个目标词从某个源词独立翻译来。
attention 可以看作「神经版的对齐模型」:\(\alpha_{ti}\) 就是软对齐分布。但 attention 不显式建模对齐结构,只是把它作为隐变量学出来。这种「软」的处理让神经 NMT 的对齐效果远超统计 NMT。
7.10 Beam Search 与解码
Seq2Seq 的解码不只是「贪心地取每步最大概率词」。贪心解码容易陷入次优——某一步的局部最优可能导致整句不通顺。
Beam search 是常用解决方案:每步保留 \(k\) 个最高概率的候选序列(\(k\) 称为 beam size,常取 4 或 5)。最后选总概率最高的完整序列。Beam size 越大,搜索质量越高,但计算量也越大。
Beam search 还有个细节:长度归一化。直接乘 token 概率会偏向短句(每多一个 token 概率乘一个 \(<1\) 的数)。Wu 2016 的 GNMT 论文用 length penalty \(\frac{(5+|y|)^\alpha}{(5+1)^\alpha}\) 校正。这种细节看似工程,对最终翻译质量影响很大。
7.11 coverage 机制
attention 模型有个「过度关注」问题:某些源端 token 被反复关注,某些被完全忽略。Tu 2016 提出 coverage 机制,跟踪每个源端位置的累计关注量,惩罚过度集中。
这是 attention 落地时的工程改进。它也启发了 Transformer 后续的研究——比如 Self-attention 是否也需要 coverage 控制?
7.12 schedule sampling
teacher forcing 训练时全程喂真实 token,导致测试时(用模型自己的预测)出现「分布漂移」:训练分布和测试分布不一致。
Bengio 2015 的 schedule sampling 方案:训练时随机选择「真实 token」或「模型预测」作为下一步输入,比例随训练进度从 100% 真实降到 50%。这种方法在 RNN 时代被广泛使用,Transformer 时代逐渐被其他方法(如 minimum risk training)替代。
八、训练 RNN 的工程经验
8.1 batching 与 padding
变长序列怎么 batch?标准做法是 padding:把短序列补到
batch 内最大长度,用一个 <PAD> token
填充。
但 padding 会浪费计算(pad 位置的计算结果被丢弃)。优化策略:
第一,bucketing:把长度相近的序列放在一个 batch 里,减少 pad 比例。
第二,packed sequence(PyTorch 的
pack_padded_sequence):让 RNN 内部跳过 pad
位置。
第三,masking loss:算 loss 时屏蔽 pad 位置,避免它们干扰梯度。
这些 trick 在 LSTM 工程里都是必备的。Transformer 时代有相应的 attention mask 接替它们的角色。
8.2 学习率
RNN 训练对学习率敏感。常见经验:
- LSTM:初始 0.001(Adam),warmup 几百步。
- 梯度裁剪
clip_grad_norm_(model.parameters(), 5.0)。 - 学习率衰减:每隔几个 epoch 减半,或者用 cosine schedule。
第 32 篇会专门讲学习率调度。
8.3 dropout
RNN 上加 dropout 比较 tricky——直接在 hidden state 上 dropout 会破坏循环结构。Zaremba 2014 的 “Recurrent Neural Network Regularization” 提出:只在 input-to-hidden 和 hidden-to-output 加 dropout,不在 hidden-to-hidden 加。这是 RNN dropout 的标准做法。
后来 Variational Dropout(Gal 2016)提出更精细的方案:同一时间步的 dropout mask 在所有时间步保持一致,理论上更合理。
8.4 layer normalization
RNN 上加 LayerNorm 也有讲究。Ba 2016 的 “Layer Normalization” 论文里就是用 RNN 做实验的。LayerNorm 让 RNN 训练更稳定,尤其是深层 LSTM。
PyTorch 没有内置 LayerNormLSTM,需要自己实现。第三方库
apex 等有 fused 实现。
8.5 stacked RNN
实践中常见的是堆叠多层 RNN:第一层的输出作为第二层的输入。深度 2-4 层是常见的,再深就不容易训了。
nn.LSTM(input_size=128, hidden_size=256, num_layers=4)更深的 RNN 可以用 residual connection(每层加跳跃连接)来稳定梯度。这是 ResNet 思想在 RNN 上的应用。
8.6 LSTM 的初始化
LSTM 的关键初始化:forget gate bias 初始化为 1(Jozefowicz 2015)。这让训练初期 forget gate 偏向「保留」,cell state 不会被清空,梯度能稳定传递。
这个 trick 简单但极其重要。PyTorch 的 nn.LSTM 默认偏置是 0,需要手动设置:
for name, param in lstm.named_parameters():
if 'bias' in name:
n = param.size(0)
param.data[n//4 : n//2].fill_(1.0) # forget gate bias = 1很多调过 LSTM 的人都吃过这个亏。
8.7 RNN 训练监控
LSTM 训练时哪些指标该监控?
第一,梯度范数:观察
clip_grad_norm_
返回的范数。如果经常被截断(远超阈值),说明训练不稳定,需要降低学习率。
第二,hidden state 范数:训练初期 \(\|h_t\|\) 应该平稳。如果指数增长说明训练发散。
第三,门激活分布:forget gate 的输出应该是双峰(0 和 1 都有),不是全 1(永远记住)或全 0(永远忘记)。
第四,loss 曲线:除了平均 loss,看「最坏样本」的 loss——RNN 容易在某些极端样本上爆 loss,平均掉看不见。
8.8 inference 加速
LSTM 推理也是串行的,没法像 Transformer 一样并行。优化方向:
第一,fused kernel:把 4 个矩阵乘合并成一个大矩阵乘。CuDNN 已经做了。
第二,low-rank:把大的 LSTM 矩阵分解成低秩近似,节省计算。
第三,量化:INT8 / INT4 部署,结合 fused kernel。
第四,batching:服务请求时多样本一起 inference,提升 GPU 利用率。但延迟敏感场景就难了。
这些优化在 GNMT、DeepSpeech 等工业系统里都用上了。但 RNN 串行的本质让加速空间有限。
8.9 RNN 与 mixed precision
fp16 训练 LSTM 比 Transformer 危险:tanh 在 fp16 下精度损失大(小数值变成 0),加上长序列的累积,常导致 NaN。
实践上 LSTM 训练经常需要 fp32,或 mixed precision 但精细 tuning。这是 RNN 的另一个工程苦点——而 Transformer 在 fp16 / bf16 下 robust 得多。
8.10 cuDNN 的 LSTM kernel
NVIDIA cuDNN 提供了高度优化的 LSTM/GRU kernel。直接调用
nn.LSTM(而非自己写一个 for loop)能利用 cuDNN
的融合实现,速度快 5-10 倍。
但 cuDNN 的实现是黑箱。如果你想做实验性 RNN 变体(比如改变 gate 公式),就不能用 cuDNN,速度会慢很多。这是 RNN 时代「定制 vs 性能」的一个工程权衡。Transformer 的 FlashAttention 走了类似的路——精心写的 kernel 大幅提升训练速度,但限制了灵活性。
8.11 训练曲线的诊断
RNN 训练曲线常出现「平台期」:loss 下降到某个值后停滞很久,再突然大幅下降。这反映 RNN 学习长依赖的非平稳过程——它先学短模式(容易),再逐渐学长模式(难)。
如果你看到这种平台期,不要急着停止训练。给它足够时间(有时是几个 epoch),它可能突然「开窍」。这种动力学在 Transformer 里也存在但不那么明显。
九、RNN 在工业界的真实使用
9.1 Google Translate 2016
2016 年 Google 上线 GNMT(Google Neural Machine Translation),是当时最大规模的 LSTM Seq2Seq 部署。8 层 encoder LSTM + 8 层 decoder LSTM + attention,参数量数亿。
GNMT 的论文(Wu 2016)是 RNN 时代工程实践的集大成者:beam search、length normalization、coverage penalty、量化推理等等技术都在里面。这是「RNN 能做到什么」的一个 ceiling。
GNMT 上线后翻译质量显著提升,被《纽约时报》大版面报道(“The Great A.I. Awakening”)。这是深度学习走入大众视野的里程碑事件之一。
9.2 ASR:DeepSpeech
百度的 DeepSpeech(Hannun 2014)和 DeepSpeech 2(Amodei 2016)用双向 LSTM 做语音识别,端到端从音频到文字。这种「不要传统 HMM-GMM 流水线」的端到端 RNN 方案当时是革命性的。
DeepSpeech 也用 CTC loss(Connectionist Temporal Classification)解决「输入输出长度不一致 + 没有显式对齐」的问题。CTC 后来在 OCR、手写识别等领域广泛应用。
9.3 早期对话系统
2015-2017 年的对话系统多用 Seq2Seq + LSTM。Vinyals 2015 的 “A Neural Conversational Model” 是早期代表,能生成符合语法但常常空洞的回答。
这些系统暴露出一个问题:用 maximum likelihood 训练的 Seq2Seq 倾向生成「安全的、通用的」回答(“I don’t know”、“I’m not sure”)。这是模式崩塌的早期表现。后来用 RL 或 retrieval-based 方法 mitigate,最终被 GPT 类大模型替代。
9.4 时间序列预测
RNN 在时间序列预测上一直是个候选方案:股价、电力负荷、传感器读数。但实证上 RNN 经常打不过经典方法(ARIMA、Prophet)或专门的工具(LightGBM)。
直到 Transformer 类方法(Informer、Autoformer、TimesNet 等)出现,深度学习在时间序列预测上才有更稳固的地位。
9.5 现在还用 RNN 吗
2024 年的现状:
- 大模型:Transformer 完全统治。
- 边缘部署:轻量场景(关键词检测、低端 ASR)仍有 LSTM/GRU 因为模型小。
- 时间序列:经典方法 + Transformer 占主流,RNN 是 baseline。
- 学术研究:RNN 几乎不再发新工作,但作为基线对比仍在用。
2023-2024 年还有「RNN 复兴」的尝试:Mamba(state space model)、RWKV(receptance weighted)等。它们试图回到「线性状态、串行更新」的范式,结合 Transformer 时代的 trick,挑战 Transformer 的地位。第 56-57 篇会展开。
9.6 Mamba 与状态空间模型
Mamba(Gu 2023)是近年最受关注的「后 Transformer」尝试。它本质上是一个连续时间状态空间模型(SSM)的离散化版本:\(h_t = A h_{t-1} + B x_t\),\(y_t = C h_t\)。看起来就像线性 RNN。
Mamba 的关键创新:让 \(A, B, C\) 与输入相关(input-dependent),获得了选择性。这让它在某些 benchmark 上接近 Transformer,且具有 RNN 一样的 \(O(N)\) 推理复杂度。
但 Mamba 在 LLM benchmark 上仍然没有完全追上 Transformer,且训练更复杂。它代表一个有趣的探索方向:把 RNN 的「线性序列」优势和 Transformer 的「表达能力」结合起来。
9.7 RWKV:另一个尝试
RWKV(Peng 2023)是另一个「类 RNN 的大模型」尝试。它把 attention 重写成可以串行计算的形式:每一步只看前一步状态,不用看完整历史。
RWKV 在推理时是 RNN(\(O(N)\)、低显存),训练时可以并行化(用一种特殊的 reparameterization)。这让它具备了「训练像 Transformer、推理像 RNN」的优点。
RWKV 仍是研究阶段,没有大规模商用,但已经有 1-14B 参数的开源模型,性能接近同规模 Transformer。这是 RNN 复兴运动的一个真实工程进展。
9.8 RNN 复兴的动机
为什么 2023-2024 年人们重新关注 RNN 类架构?三个原因:
第一,长序列推理成本:Transformer 的 KV cache 在长序列下占内存巨大,每生成一个 token 要 \(O(N)\) 计算。RNN 类架构是 \(O(1)\) 每步。
第二,理论好奇:Transformer 的 \(O(N^2)\) attention 真的是「最优」吗?是否存在能匹敌它但更高效的架构?
第三,Mamba 的实证突破:Mamba 在某些 benchmark 上首次接近 Transformer,让人们相信 RNN 类架构有翻盘机会。
未来如何?没人知道。但「RNN 已死」的判断显然过早。
9.9 RNN 在多模态中的角色
RNN 时代有一些经典的多模态模型:图像描述(image captioning,Vinyals 2015 的 Show and Tell)、视频理解、语音-文本对齐等。这些模型的共同结构是「编码器(CNN/RNN 处理输入模态)+ RNN 解码器(生成文本)」。
进入 Transformer 时代,这种结构被 ViT + Transformer decoder 等架构取代。但 RNN 时代的多模态思路(用一个共享表示空间连接不同模态)影响了后续的 CLIP、BLIP 等工作。
9.10 RNN 的教学价值
即使 RNN 在工业上被 Transformer 取代,它在教学上仍有不可替代的价值。学习 RNN 让你直观理解:什么是「时间」,什么是「状态」,什么是「记忆」,什么是「梯度沿时间传播」。
这些概念在 Transformer 里以更隐晦的形式存在。特别值得回味的是记忆的区别:RNN 把过去所有的序列信息都压缩、融合进一个固定维度的隐藏状态 \(h_t\) 中(这是一种有损压缩的隐式记忆);而 Transformer 凭借它的 KV Cache,直接把过去每一个时间步的无损特征向量全部平铺缓存下来(这是一种无外置查找的显式记忆)。从「压缩记忆」走到「随时查阅的外置记忆」,也是深度学习对内存和算力权衡观念转变的见证。先学 RNN 再学 Transformer,自然就能体会出这道架构更替背后的必然性。
9.11 RNN 在边缘设备上的优势
RNN 在边缘设备(手机、IoT、嵌入式)上仍有竞争力。原因:
第一,参数量小(百万级 LSTM 已经能做不少任务);
第二,推理时不需要存 KV cache(Transformer 的长上下文 KV cache 在边缘设备上是大问题);
第三,逐 token 推理的延迟稳定(不像 Transformer 的延迟随上下文长度线性增长)。
苹果、Google 等公司在端侧的语音识别、智能键盘等场景仍大量使用 LSTM/GRU 的变体。这是 RNN 不会消失的另一个理由——它在「资源受限」场景下的归纳偏置仍然合适。
十、关键概念回顾
RNN 的故事跨越了 30 年,从 Elman 1990 到 Transformer 2017。它的核心思想是用「循环 + 权重共享」处理变长序列,让网络获得「记忆」。Vanilla RNN 提供了基础结构 \(h_t = \tanh(W_h h_{t-1} + W_x x_t)\),简洁优雅,但被「梯度消失爆炸」拖住。
LSTM 1997 年用三门 + cell state 解决梯度消失,给 RNN 注入了能学几百步依赖的能力。GRU 2014 是 LSTM 的简化版,效果接近、参数更少。门控机制后来超越 RNN,成为深度学习的通用工具——ResNet、Highway、Transformer 的某些组件都能从「门控」的视角理解。
Seq2Seq 2014 把 RNN 推到「输入序列 → 输出序列」的通用框架,催生了 NMT、对话、摘要等一系列应用。Bahdanau 2014 的 attention 修补了 Seq2Seq 的 context bottleneck,并意外开启了 Transformer 之路。
工程上 RNN 有一堆技巧:gradient clipping、forget bias=1、teacher forcing、bucketing、stacked layers。这些细节让 LSTM 在 2014-2017 年支撑了几乎所有重要 NLP 系统。Google Translate 2016 是 RNN 时代的工程巅峰。
但 RNN 有结构性问题:训练不能并行、长程依赖仍然有限、内存随序列线性增长。这些问题在 Transformer 之前没有根本解。下一篇我们就会展开这些根本局限。
十一、下一步
RNN 的故事铺到这里基本完整。它从 Elman 1990 的 simple recurrent network 起步,经过 LSTM 1997 的门控革命,到 2014-2017 的 Seq2Seq+attention 黄金时期,再到 2017 Transformer 的颠覆,最后是 2023 Mamba/RWKV 的复兴。这是一段三十多年的旅程,每一步都有对应的「为什么这样做」的工程动机。
下一篇我们要回答:RNN 的根本局限是什么?为什么需要 Transformer 这种全新范式来取代它?
10 RNN 的根本局限 会从「长程依赖 / 梯度稳定 / 训练并行」三个角度系统分析 RNN 的天花板,然后讲 Bahdanau attention、Luong attention 如何作为「补丁」逐步把 RNN 推向极限,最后讲 Vaswani 2017 怎么完全抛弃循环、用纯 attention 解决问题。
之后第 11、12、13 篇会专门展开 attention 机制本身。这是 Transformer 的核心。
学完这两篇,你就具备了理解 Transformer 论文 “Attention Is All You Need” 的全部前置背景:从 Embedding、Softmax、Backprop 到 RNN、LSTM、Seq2Seq、attention,每一块都到位。
十四、参考文献
- Elman, J. L. (1990). Finding Structure in Time. Cognitive Science. RNN 早期工作。
- Hochreiter, S., Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation. LSTM 论文。
- Bengio, Y., Simard, P., Frasconi, P. (1994). Learning Long-Term Dependencies with Gradient Descent is Difficult. IEEE TNN. 梯度消失分析。
- Pascanu, R., Mikolov, T., Bengio, Y. (2013). On the Difficulty of Training Recurrent Neural Networks. ICML. 梯度爆炸与裁剪。
- Cho, K. et al. (2014). Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. EMNLP. GRU 论文。
- Sutskever, I., Vinyals, O., Le, Q. V. (2014). Sequence to Sequence Learning with Neural Networks. NeurIPS. Seq2Seq。
- Bahdanau, D., Cho, K., Bengio, Y. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. ICLR. 第一次把 attention 用到 NMT。
- Luong, M.-T., Pham, H., Manning, C. D. (2015). Effective Approaches to Attention-based Neural Machine Translation. EMNLP. attention 变体比较。
- Schuster, M., Paliwal, K. K. (1997). Bidirectional Recurrent Neural Networks. IEEE TSP. 双向 RNN。
- Greff, K. et al. (2017). LSTM: A Search Space Odyssey. IEEE TNN. LSTM 变体大比拼。
- Wu, Y. et al. (2016). Google’s Neural Machine Translation System. arXiv. GNMT。
- Jozefowicz, R., Zaremba, W., Sutskever, I. (2015). An Empirical Exploration of Recurrent Network Architectures. ICML. forget bias=1 等技巧。
- Zaremba, W., Sutskever, I., Vinyals, O. (2014). Recurrent Neural Network Regularization. arXiv. RNN dropout。
- Karpathy, A., Johnson, J., Fei-Fei, L. (2015). Visualizing and Understanding Recurrent Networks. ICLR Workshop. LSTM 神经元可视化。
- Tu, Z. et al. (2016). Modeling Coverage for Neural Machine Translation. ACL. coverage 机制。
- Bengio, S. et al. (2015). Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks. NeurIPS. schedule sampling。
- Le, Q. V., Jaitly, N., Hinton, G. E. (2015). A Simple Way to Initialize Recurrent Networks of Rectified Linear Units. arXiv. IRNN。
- Vinyals, O. et al. (2015). Show and Tell: A Neural Image Caption Generator. CVPR. 图像描述。
- Gu, A., Dao, T. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv. Mamba。
- Peng, B. et al. (2023). RWKV: Reinventing RNNs for the Transformer Era. arXiv. RWKV。
上一篇:08.5 神经网络基础
下一篇:10 RNN 的根本局限
同主题继续阅读
把当前热点继续串成多页阅读,而不是停在单篇消费。
【Transformer 与注意力机制】10 RNN 的根本局限:为什么需要 Transformer
RNN 三难(长程依赖、梯度稳定、训练并行)的系统分析;attention 如何作为补丁逐步把 RNN 推向极限;Vaswani 2017 抛弃循环的范式革命
【Transformer 与注意力机制】08.5 神经网络基础:从 MLP 到 RNN 的最后一块地基
用 6 张 matplotlib 图和一个真实可运行的 toy MLP,把神经网络从单神经元、前向传播、损失函数、反向求导、梯度下降、NumPy/PyTorch 实现一路讲到为什么序列任务最终需要 RNN。
【Transformer 与注意力机制】58|后 Transformer 时代:架构会消失还是会进化
后 Transformer 时代不太可能是某个新架构一夜之间消灭 Transformer,更可能是 attention、SSM、MoE、检索、外部记忆、工具调用和多模态模块逐渐混合。本文回顾本系列主线,解释为什么 Transformer 很难突然消失,也为什么它不可能原样解决所有问题。
【Transformer 与注意力机制】59|推理退化:为什么大模型会输出乱码、死循环和无意义文本
大模型推理时偶尔会突然陷入死循环、输出乱码或连续无意义数字,这不是随机 bug,而是注意力机制、Causal Mask、解码策略和数值精度在自回归生成中共同作用的结果。本文从 QKV 计算坍塌出发,解释 Attention Sink、Softmax 马太效应、Causal Mask 的退路切断、FP16 溢出路径和 KV Cache 污染,并给出从架构到运行时的多层防线。